2022年3月16日改訂
2001年5月25日
教育・研究・市民アセスメント用空間情報システム
「みんなでGIS」 Minna de GIS
小池文人
koikef@orange.ocn.ne.jp
Copyright (c) 2001-2022, Fumito Koike
ダウンロード 2022年3月16日改訂版
プログラムとマニュアル,システムファイルのインストーラー(初めてのとき,7.6 MB)
プログラムとマニュアルのみ(いったん上記でインストールが必要,5.0 MB)
文字化けやモジュール不足による異常終了が起きるため,いったんSETUPプログラムでインストールしてください.
目次
1.はじめに
1.1 地理情報システムについて(GIS, Geographic Information System)
1.2 「みんなでGIS」の方針
1.3 システムの概要
1.4 作業の進め方
1.5 使用条件
1.6 必要なパソコン
1.7 予約されている変数名やファイル名
2.使い方の解説
2.1.1 インストールと起動
2.1.2 変数名の変更や,座標が数値として得られている場合のファイル作成
2.1.3 [経緯度電卓]
画像ファイルに出力
2.2 画像ファイルに書き出す (R・V→画像)
データ入力編集・空の図形の発生
<データ入力・編集>
2.3.1 地図や空中写真の画像のとりこみ (画像→R)
2.3.2 地図や写真上の地点や領域などをマウス入力 (R→V)
2.3.3 GPSなどの緯度経度の地点データの一括読み込み (外部→V)
2.3.4 プローブ用のデータ発生 (→R・V)
2.3.5 投影方法を変更しながら画像読込(古い5万分の一地形図など) (画像→V)
<市販・公共データの読込>
2.4.1 標準地域メッシュ旧テキスト(csv)の読込.国土数値情報人口など各種(公共・外部→V)
2.4.2 XMLファイル(GML)の読込.国土地理院10mDEM,国土交通省100m土地利用(公共→R・V)
2.4.3 50mメッシュ標高データ「数値地図50mメッシュ(標高)」の読込 (市販→V)
2.4.4 10mメッシュ標高データ「GISMAP Terrain」の読込 (市販→V)
2.4.5 世界30秒メッシュ(約1km)標高データ「GTOPO30」の読込 (市販→V)
2.4.6 海底も含む世界30秒メッシュ(約1km)標高データ「SRTM 30 Plus」 (公共→V)
2.4.7 1kmメッシュ気候統計値の読込 (市販→V)
2.4.8 土地利用図「細密数値情報(10mメッシュ土地利用)」の読込 (市販→R・V)
2.4.9 土地利用図「細密数値情報(10mメッシュ土地利用)」の読込 広域の集計(市販→R)
2.4.10 全国植生調査3次メッシュデータ(1kmメッシュ)の読込 (市販→V)
2.4.11 数値地図2500(空間データ基盤)町丁目・道路・鉄道・水域等の読込 (市販→V)
2.4.12 2万5千分1地形図地図画像「数値地図25000(地図画像)」の読込 (画像→R)
2.4.13 2万5千分1地形図の市販CD画像の色を紙地図的に変換 (R→R)
2.4.14 CADのDXFファイルを「みんなでGIS」のベクトルファイルに変換 (外部→V)
属性値の計算とファイル統合
<ファイルの統合と変数の演算>
2.5.1 ラスタ変数の演算と統合 (R→R)
2.5.2 ベクトルファイルの統合 (V・外部→V・外部)
2.5.3 ベクトルファイルの変数の演算 (V→V)
2.5.4 ベクトルファイルのリストを表に変換 (V→V)
2.5.5 ベクトルファイルの表をリストに変換 (V→V)
<属性値の空間的な集計>
2.5.6 図形が最近接する他の図形やセルの属性値を取得 (R・V→V)
2.5.7 一定距離内の図形やセルの属性値を集計して,図形に付与 (R・V→V)
2.5.8 一定距離内の図形やセルの属性値を集計して,セルに付与 (R・V→R)
かたちの情報の変換と計算
<図形と座標の操作>
2.6.1 等値線作成と領域を多角形として取得 (R→V)
2.6.2 ベクトル図形のタイプの変更 (V→V)
2.6.3 座標軸の平行移動と回転 (R→R,V→V)
2.6.4 個々の図形の平行移動と回転 (V→V)
2.6.5 図形を属性値で指定した数だけコピー (V→V)
<幾何特性の計算>
2.6.6 図形の幾何的な特性を計算 (V→V)
2.6.7 図形間の距離 (V→V)
2.6.8 不均一環境での図形間の時間距離 (V・W→V・W)
<ベクトルとラスタのあいだの高速な変換>
2.6.9 point地点のラスタ情報を収集 (R→V)
2.6.10 point地点のデータを補間してラスタに (V→R)
2.6.11 ラスタをタイルpolygonに (R→V)
<属性値から図形を作成>
2.6.12 属性値を座標とするpointを作成 (V→V)
2.6.13 属性値を中心座標や半径とする円形のpolygonを作成 (V→V)
その他・応用プログラム
<統計>
2.7.1 属性値によるサンプル(図形)の自動分類 (座標づけ分割法) (V→V)
2.7.2 ロジスティック回帰 (V→)
2.7.3 最大値回帰 (V→)
2.7.4 個体数の期待度数との差の検定 (カイ2乗検定) (V→)
2.7.5 図形の再サンプリング (V→V・外部)
2.7.6 個体の自動配属 (V→)
2.7.7 領域の統合型クラスター回帰 (V→V)
2.7.8 外来生物の侵入順序解析−過去の歴史による分布拡大予想 (V→V)
<メタ個体群動態>
2.7.9 個体群の拡大過程(メタ個体群のシミュレーション) (V→V)
2.7.10 外来種の空間的な最適制御戦略 (V→V)
2.7.11 種子散布カーネルを求める (V→)
<地形環境>
2.7.12 地形データをもとにした日射量の計算 (R→R)
2.7.13 地形データをもとにした集水量の計算 (R→R)
<野外調査支援>
2.7.14 ラインセンサスの座標計算 (外部・V→V)
2.7.15 同一地点で重複測定したデータをリストに変換 (特殊→外部)
<地理座標を使わない特殊な解析>
2.7.16 図形間距離の尤度分布から地図再構築 (特殊→V)
2.7.17 頻度からの尤度による傾度分析 (外部→特殊)
2.7.18 一対比較による傾度分析 (外部→)
2.7.19 出現頻度の尤度分布分析 (V→V)
2.7.20 遺伝子頻度から導入個体数推定 (外部→特殊)
2.7.21 類似度JaccardCC (V→V)
<天球をあつかうもの>
2.7.22 全天写真の自動読み取り「空と森」 (特殊→特殊)
2.7.23 天球を等面積に分割 (→V)
2.7.24 天球の輝度分布を逆推定 (特殊→特殊)
2.7.25 葉群密度測定用レーザースキャナ (→特殊)
<その他>
2.7.26 確率計算器
2.7.28 中央値のブートストラップ検定
3.使用例
3.1 地図上の任意の位置の座標(平面直角座標)を調べる
3.2 ラスタデータ(画像,メッシュ値)からベクトルの格子データへの変換
3.3 ベクトルの格子データからラスタデータへの変換
3.4 生物の生育環境の解析と分布予測図の作成(GAP分析など)
3.5 細切れに撮った写真や分割してスキャナ入力した画像を1枚に貼合わせる
3.6 空中写真を使った植生のタイプ分け(自動分類)
3.7 空中写真を使った地被のタイプ分け(トレーニングエリア)
3.8 いくつかの地点で測定した気温のデータから地域全体の気温分布図を描く.
あるいは測量結果からDEMをつくる.
3.9 等高線が描かれた紙の地形図からメッシュ高度データ(DEM)を作成する
3.10 土地の傾斜の計算や,画像のエッジ検出など
3.11 生物のマッピング結果から重要な地域を検出する
3.12 干潟や湖沼の浮葉植物の分布を調べる
3.13 汚染物質の拡散予測
3.14 生育地保全のための集水域の重要度評価
3.15 GPSを使用して森林で樹木の位置をはかり胸高直径を円の大きさ,雌雄を色で表示
3.16 GPS測定地点からの距離と方位で植物のマッピングをしたとき
3.17 長方形の調査地の原点でGPSによって緯度と経度を計った
3.18 スクリーントーンを貼ったように見える地図をつくる
4.データ構造
4.1 ベクトル・ファイル(図形)
4.2 ラスタ・ファイル(画像・メッシュ値)
5.空中写真や地図の入手先,情報源など
6.謝辞
7.Q&A
8.プログラムの改訂履歴
目次の項目の後のカッコ内の矢印は,処理前と処理後のデータの形式を示す.
R ラスタ・ファイル(画像・メッシュ値)
V ベクトル・ファイル(点,折線,多角形などの図形)
画像 24bitカラーのWindowsビットマップ・ファイル
市販 市販データ
外部 変数名を先頭行に置いたCSVファイル
1.はじめに
市民参加で地域の自然を調べる試みが広がっている(浜口哲一著,生きもの地図が語る街の自然,岩波書店http://www.iwanami.co.jp/.BOOKS/00/7/0066610.html).また,生態学の研究でも景観生態学の発展で,景観を意識しない研究は難しくなっている(生態学での「景観」は畑や森などの異質の環境がモザイクのように混在したもので,造園分野での見た目の「景観」とは全く意味が異なる.ただし景観生態学の研究は生態学会だけでなく造園学会でもさかん).ところが調べた結果を解析したり,結果を表示するのに適当なソフトウェアはあまりない.市販のGISシステムは特殊な業務用のソフトとして位置づけられているため基本的なもので30万円もしていて,逆に安価に配布されているものでは表示中心で解析のできないものもある.そのため簡単なGISシステムを自作してみた.
1.1地理情報システムについて(GIS, Geographic Information System)
GISと呼ばれているソフトにもさまざまなものがある.ひとつはラスタ・データで表現される画像処理や地形処理を得意とするもので,Unixで使える無料のGrass(http://www.baylor.edu/grass/)や,非営利団体が管理していて比較的安価なIDRISI(http://www.clarklabs.org/)などが有名である.他方では多角形などの図形のベクトル・データを得意とするものもあり,市役所などで土地登記情報の管理や道路工事での地下の配管情報の管理,企業の商圏の解析などに使われている(http://www.gis.pasco.co.jp/).また統計解析が得意なソフトもある(http://www.msi.co.jp/splus/tips/spatial/frame.html)
「空間データを扱う」というのがGISの共通点で,データの入出力と編集に関しては共通である.しかし実際に行う処理は分野によって全く違っている(たとえば登記簿管理と地形の浸食速度の推定,など).実際に利用できる解析手法は各システムごとに違っていて,万能のGISシステムは存在しない.利用者の少ない分野の解析手法が汎用のGISシステムに組み込まれる可能性は低く,仮にオプションとして利用可能であってもきわめて高価なものになる.そのため生態学研究者は,少なくとも現在の時点では,自分の研究のためにプログラムを自作する必要がある場合も多い.(ちなみに,長い歴史があって利用者も多いと思われる研究用の統計ソフトやグラフ作成ソフトにしても未だに決定版はない点から考えると,マイナーな機能が将来的に汎用GISシステムに組み込まれることは期待できない.)
今後は,(1)GISの自作があるていど広まり,(2)さまざまなフリーやシェアウェアのソフトが現れ,(3)それぞれの分野ごとに「本当に必要な機能は何か」というコンセンサスができてゆき,(4)このコンセンサスをもとにソフトの機能が収斂し,(5) フリーやシェアウェアの中から次の世代のスタンダードとなるソフトが現れる,というような経過をたどるのではないだろうか.ちなみに「みんなでGIS」はスタンダードを目指さないが,さまざまな機能を提案することで,必要な機能のコンセンサスが成立する過程に貢献できればよい.
なお,海外のフリーのGISソフトやツールなどの情報を集めたサイトもある(http://www.freegis.org/index.en.html).GISに関するサイトのリンク集である「GIS school (http://gisschool.csis.u-tokyo.ac.jp/)」や,国産のいくつかのフリーGISの紹介をはじめとして,いろいろな情報が充実している広島大学総合科学部自然環境科学講座のサイト(http://home.hiroshima-u.ac.jp/er/soft.html)も役立つ.日本地図センターでは販売する地図データを利用できるソフトの一覧表を公開しているが,このリストが日本のGISソフトの一覧表にもなっている(http://www.jmc.or.jp/soft/list/allsoft.html).
1.2 「みんなでGIS」の方針
1. 自分が集めた範囲のデータを自分で自由に解析するための,小規模で自由なソフトを目指す.大きなデータベースと連携した処理や定型的な業務上の処理は想定しない.
2. なるべく簡単なソフトにして,解析では他の表計算ソフトや統計ソフトなどを最大限使う
3. 人間がデータをエディタや表計算ソフトなどで直接書けるように,人間可読のデータとする
4. 管理が簡単なように,ひとつのファイルでデータが完結するようにする
5. 直交座標を使い,座標系は中学の数学と同じにする(画面の左上隅が原点になるパソコンの画面座標とは上下が逆になる).表記だけの問題だが,日本における書物やふつうの緯度経度からの座標変換プログラムでは,都市計画図の平面直角座標は北がxで東がyとして表現されていて,xとyが逆なので注意が必要.裏返しになっているので回転しても重ならない.海外ソフトにはこのプログラムと同方向のものもある.
6. 野外の生物の成育場所の解析を中心的な目的にする(他の目的にも使えるが)
1.3 システムの概要
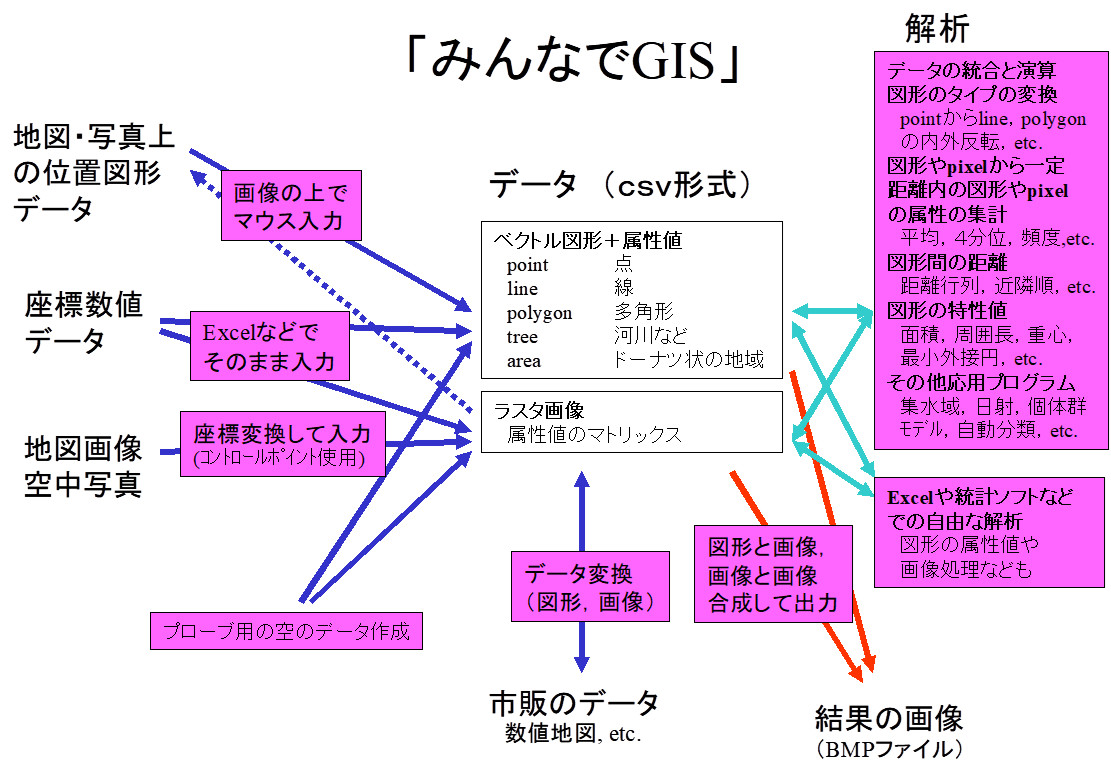
データはコンマ区切りのテキストであるCSV形式で,図形(ベクトル・データ)と画像などの面的なデータ(ラスタ・データ)は別のファイルになる(図1).
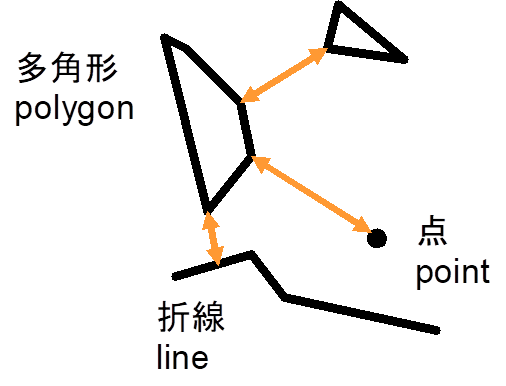
基本的な図形(ベクトル・データ)には点を表すpoint,折線を表すline,多角形を表すpolygonがあり,さらに折線を組み合わせた木の形のtreeは河川などを,多角形を組み合わせたareaはドーナツ状の地域を表現する.図形ごとに属性値(図形が生物の生育地のハビタットであるとすれば,生物の種類や個体数などの情報)を持つ.polygomとpointなどの異なったタイプの図形をひとつのファイルに含むことができる.
画像などの面的なデータ(ラスタ・データ)は属性値の表(行列)になる.カラーの画像では3原色のred, green blueの3つの属性変数を含むが,さらに多数の変数をひとつのファイルに含むこともできる.
地図上で物差しで測定した座標や,GPSなどで測定した座標値は,Excelなどを使ってデータのファイルに直接書き込む.スキャナで取り込んだ地図の画像や空中写真は,座標が既知の地点をコントロールポイントとして座標変換し,ラスタ画像に取り込む.地図や写真の上に書き込まれた位置や図形は,いったん画像をラスタ・データにした後で,それを背景に表示しながらマウスで位置を入力することができる.
図形間の距離や,図形の周辺の属性値の収集,図形の面積などを求める計算ができる.また不規則な測定地点での実測値を補間して地域全体での分布を見たり,数地点の測量結果から地形全体の標高のメッシュデータ(DEM)を作成することができる.データはCSVファイルなのでExcelを使った図形の属性値の処理や画像処理,他の統計ソフトの利用,自作プログラムでの処理,などができる.
結果を画像として利用する場合はWindowsのBMP形式(ウィンドウズ・ビットマップ)で保存し,他の写真レタッチソフトで印刷する.BMP形式では用紙1 mあたりの画素(ピクセル)数をファイルの先頭にあるヘッダ内に指定できるので,アドビ社(http://www.adobe.co.jp/main.html)のPhotoshop Limited Editionなどの数千円程度の安価版のソフトを使えば地図の縮尺も正確に印刷できる.縮尺を生かして印刷できるソフトは意外に少ないが,とても高価なPhotoshopのフルセットは必要ない.ちなみにWindows標準添付のペイントブラシでも印刷はできるが,縮尺は反映されない.
地理的な座標には,日本全国を19の地域に分割して横メルカトル図法で計算した「平面直角座標(19座標)」か,地球全体を南北の短冊切りにした横メルカトル図法のUTM座標を使うのがよいとおもう.国土地理院の1:25000や1:50000地形図はUTM座標であり,それより詳細な国土地理院の1:10000地形図や市役所などで販売している1:2500都市計画図(地形図),営林署で販売している国有林の1:5000地形図などは平面直角座標を使っている.平面直角座標を使っている地図は外枠に座標値をkm単位で記載していることが多い.
|
図1.1 システムの概要 |
1.4 作業の進めかた
1. まず,何をやりたいのかを明らかにしておく.どんな出力結果がほしいのか,どんな解析をしたいのか.
2. あらかじめ処理の手順を考えておく.どんなデータを元に,どんな処理を組み合わせるか.「みんなでGIS」はなるべく一般性の高い単純な道具で構成するように心がけているので,基本的な処理を柔軟に組み合わせて工夫しながら,必要な処理を実現することになる.
3. なるべく頻繁に画像ファイルに出力したり,データファイルをExcelでみたりして,データを確かめながら作業を進める.
4. 紙の上に鉛筆で略図を書いたり,座標値のメモをしながら作業を進めるとよい.座標を入れて図を描く場合には方眼紙にレイアウトしてみることも有効.
5. 座標系(平面直角座標かUTMか,日本測地系か世界測地系か)は作業を始める前にあらかじめ決めておく.入手可能なデータと(現在はまだ日本測地系のデータが多い),最後に出力する地図から総合的に判断する.最後の出力結果を国土地理院の2万5千分の一地形図に載せるならUTMだが,それ以外の場合は基本的に平面直角座標がよいと思う.ただし,等高線の入った背景地図はDEM(メッシュ標高データ)をもとに自分で作った方がよく,この場合は座標系を自由に選べる.生態学関係の学術雑誌では市販の地図にデータを表示したものは掲載してくれないことが多く,以前は等高線を自分でトレースしていたが,GISを使ってDEMから作るととても楽だ.
|
|
作業用のメモの例 GISに取り込む必要のある座標の範囲や必要な解像度などを決める |
1.5 使用条件
使用者は研究者や市民を想定しています.意図しないデータの消失やプログラムのバグがあるかも知れませんが,損害は補償できないので自己責任での使用をお願いします.なお,普通の市販ソフトと違って,既存のファイルに上書きする場合も警告を出していません.
このシステムを使用してレポートや論文を作成した場合は,その旨を文中に記載・引用しておいてください.
このプログラムは他に再頒布せず,次のサイトからダウンロードしてください.http://www. minnagis.com
1.6 必要なパソコン
VisualBasic6.0で作成したアプリケーションなので,マイクロソフトWindows 7,8,10(64ビット版も)などで利用できる. MacでもWindowsのコピーを使うBootcampのほか,さらに手軽なWineでも利用可能.なおVisualBasic6.0の開発システムは「データアクセスコンポーントをインストールしない」オプションと「管理者として実行」プロパティでの起動によりWindows10(64ビット版も)でも利用可能.Windows10では,管理者としてログインしていても通常のダブルクリックなどの起動では一般ユーザーになってしまうため,明示的に右クリックから「管理者として実行」を選ぶか,実行ファイルの互換性プロパティで「管理者として実行」を指定しておく.
パソコンは基本的なもので十分である.ディレクトリを分けるなどでファイル名のバッティングを避ければ,多数の「みんなでGIS」を同時に起動して実行できる.HDDは,画像を含めてデータがテキストファイルであるため,データを置くには大きな容量が必要だが,圧縮フォルダにしておけば圧縮率はとても高いので小さなドライブでも十分である.
なおA4サイズ程度のスキャナなどの画像入力の手段やExcelなどの表計算ソフト,結果を正確な縮尺で印刷するための写真レタッチソフトも必要になることが多いと思う. A0サイズなどの大きな地図のスキャナ入力は大きな図面のコピーをやってくれるキンコーズなどの店に依頼すれば,手頃な値段で入力してくれる.
1.7 予約されている変数名やファイル名
このシステムの中では以下の変数名は使えない.ここでは大文字・小文字は区別されない.
type$, name$, NodeNum
「みんなでGIS」を起動時のカレント・ディレクトリ(ふつうはプログラム本体のMinnaGIS.EXEがあるディレクトリや,ショートカットのプロパティで指定した作業フォルダ)に以下の名称のファイルをおくと一時ファイルやログファイルに使われるため,無条件に書換え・削除されます.
temp1.tmp, temp2.tmp, temp3.tmp, temp4.tmpなど, bmp1.bmp, RasterFileSize.log, VectorFileSize.log, tmpPointList.txt, tmpParamList.txt, BmpLoad.log.csv
2.使い方の解説
2.1.1 インストールと起動
初めてインストールする場合
1. 文字化けを避けたり,MSCOMM32.OCXなどをインストールする必要があるため,必ず一度はSETUPプログラムでのインストールを行う.SETUPプログラムでインストールする場合は,Windowsの管理者としてログインする.Windows10では,管理者としてログインしていても通常のダブルクリックなどの起動では一般ユーザーになってしまうため,明示的に右クリックから「管理者として実行」を選ぶか,実行ファイル(setup.exe)の互換性プロパティで「管理者として実行」を指定しておく.この作業を行わなくても利用可能な機能はあるが, GPSを利用可能な[経緯度電卓]などで「MSCOMM32.OCXがない」とのメッセージが出る場合や文字化けが起きる場合はインストール作業が必要である.
2.
ダウンロードした解凍ファイル(instgis.zip)を解凍する.なかのファイル名は以下の通り.
MinnnaGIS.EXE プログラム本体
setup.exe セットアップ用のプログラム
SETUP.LST セットアップ用の設定ファイル
MinnnaGIS.CAB 必要なプログラムが入っている圧縮ファイル
manual.pdf マニュアル(アクロバットリーダーで読む)
VectorSample.csv ベクトルファイル(図形)のサンプル
RasterSample.csv ラスターファイル(画像,メッシュ値)のサンプル
auxfile.csv 外部ファイル(統計ソフト等)のサンプル
都道府県vector.csv 日本地図のサンプル.座標系は内部のコメント参照
3. setup.exeをダブルクリックしてセットアップする.圧縮ファイルに入っていたMinnaGIS.EXEが適当なディレクトリにコピーされ,VisualBasicのランタイムとしてVB6JP.DLLやRS-232CをコントロールするためのMSCOMM32.OCXと MSCOMJP.DLLがシステム・ディレクトリにコピーされる.
4. プログラム本体はMinnaGIS.EXEである.いったんインストールすれば(すなわちVB6JP.DLLやMSCOMM32.OCXなどがWindowsディレクトリにコピーされれば)MinnaGIS.EXEを他のディレクトリに移動しても動く.
5. 効率よく仕事を行うには,(a)データのあるディレクトリにMinnaGIS.EXEをコピーしてデータといっしょに置くか,あるいは,(b) MinnaGIS.EXEのショートカットをデータのあるディレクトリなどの適当な場所に作製して,ショートカットのプロパティの[作業フォルダ]をそのディレクトリに書き換えておく,などのどちらかの対応をしておくと以後の作業が楽である.修正プログラムの再インストールを考えると(b)がおすすめ.
6. Windows10では,MinnaGIS.EXEファイルを右クリックして「互換性プロパティ」で「管理者として実行」(あるいはWindowsXP互換など)を指定しておく.
7. 上記3番で作製したショートカットか,データのあるディレクトリのMinnaGIS.EXEファイルをダブルクリックするとプログラムを起動できる.Windows10でDLLやOCX関係のエラーメッセージが出る場合は,右クリックから「管理者として実行」を選ぶか,上記のように実行ファイルの互換性プロパティで「管理者として実行」を指定しておく.
8. インストールが終わったら,とりあえず標準添付のデータを[画像ファイルに出力]してみると良いかもしれない.VectorSample.csvはファイルを指定して[読込]してから「変数1」を赤緑青のどれか(複数でも良い)に割り振って指定し,[実行]する.RasterSample.csvはファイルを指定して[読込]してから「変数1」を赤緑青などに指定し,画素サイズを0.05程度に変更してから[実行]する.またVectorSample.csvやRasterSample.csvをダブルクリックすれば,データをExcelで直接みることができる.
9. データのファイルの書式が違っていて読込に失敗したときは,プログラム起動時のカレントディレクトリ(ショートカットの作業フォルダか, MinnaGIS.EXEがあるディレクトリ)に,読込の経過を記録したVectorSize.log(ベクトル図形ファイルの場合)かRasterSize.log(ラスタ画像ファイルの場合)という名前のファイルが残されている.これをダブルクリックしてエディタやワープロで見れば,データのどの部分に問題があるのかがわかる.
10. 最近のWindowsで多いトラブルとして,フォームを全画面表示すると異常終了することがあった(内部でサイズ変更しているため).2016年12月14日以降の新しいバージョンで対策済み.
11. Nortonのセキュリティソフトは不審プログラムとしてminnagis.exeを削除しようとするので回復する.(小規模の企業による新しいプログラムはビルドごとに別のものと認識されて基本的に自動削除されるとのこと).ダウンロードしたMinnaGIS.EXEファイルを起動しようとするとWindows Defenderも拒否するので必ずインストール作業を行う.
新しいバージョンをインストールする場合(2回目以降のインストール)
1. SETUPプログラムによって少なくとも一回インストールした場合はVisualBasicのランタイムのVB6JP.DLLやMSCOMM32.OCXなどはすでにシステムに入っているので,プログラム本体の MinnaGIS.EXEを以前のバージョンの上に上書きコピーすればよい.ただしダウンロードするサイズが大きくても良いのであれば,初めと同じようにSETUPを実行しても良い.
2. 文字化けが起きたり,[経緯度電卓]などで「システムファイルがない」旨のメッセージが出て異常終了する場合は上記のSETUPプログラムでシステムファイルをインストールする必要がある.
3.
ダウンロードした自己解凍ファイル(instgisXP.zip)を解凍する.内部のファイル名は以下の通り.
MinnnaGIS.EXE プログラム本体
manual.pdf マニュアル(アクロバットリーダーで読む)
VectorSample.csv ベクトルファイル(図形)のサンプル
RasterSample.csv ラスターファイル(画像,メッシュ値)のサンプル
auxfile.csv 外部ファイル(統計ソフト等)のサンプル
都道府県vector.csv 日本地図のサンプル.座標系は内部のコメント参照
|
|
図2.1 たちあげたとき
|

2.1.2 変数名の変更や,座標が数値として得られている場合のファイル作成
1. Excelやテキストエディタでファイルを作成・変更する.フォーマットは後述の「4.データ構造」を参照
2. 属性変数の欠損値には文字でnullと入れるか,ベクトルファイルではそのまま空きにしておいても良い(空白文字はいけない).ラスタファイルは必ず文字でnullと入れる.
3. 情報はファイルひとつの中だけに保存されているので,形式があっていれば自由に書き換えて良い.(他のGISでは複数のファイルに情報が分散していることが普通)
4. ExcelでCSVファイルに保存したものをエディタで見ると,行末にコンマが連続してついているが,これは自動的に削除されるのでかまわない.ただしファイル末にコンマだけの行がある場合は異常終了する.
5. GPSなどによる緯度経度の測定結果から直交座標の19座標系(1:2500都市計画基図など,国内に原点が19個ある横メルカトル投影)や,UTM座標系(国土地理院1:50000地形図,1:25000地形図などの横メルカトル投影)への変換は[経緯度電卓]で行う.なお,GPSで測定した世界測地系の緯経度を旧日本測地系の19座標系に変換する場合は,国土地理院のサイトなど(http://vldb.gsi.go.jp/sokuchi/tky2jgd/)で世界測地系経緯度から日本測地系経緯度への変換を行ってから[経緯度電卓]を使う.
2.1.3 [経緯度電卓]
1. 緯度・経度から平面直角座標(都市計画図)やUTMの座標,地域メッシュ・コードをもとめるなど,ちょっとした計算を行うための電卓を用意した.
2.
座標系は日本測地系(旧)か世界測地系(日本測地系2000)である.以下の計算ができる.
日本測地系の経緯度 → 日本測地系の平面直角座標かベッセル楕円体のUTMと,
日本測地系の地域メッシュ番号
世界測地系の経緯度 → 世界測地系の平面直角座標かGRS80楕円体のUTMと,
世界測地系の地域メッシュ番号
世界測地系の経緯度(GPSなど)から日本測地系の経緯度への変換は,国土地理院のサイトでできる(http://vldb.gsi.go.jp/sokuchi/surveycalc/).測地系によって,同じ地点であっても平面直角座標や地域メッシュ番号が変化する.
3. 平面直角座標を求めるには,日本の都市計画図の19座標系では第1系から第19系まで,またUTM座標系では経度6度ごとに切られたUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく(都市計画図とUTM座標では原点とともに若干のパラメータが違う.精度は日本の19座標系の方が高い).
4. 緯度と経度を度分秒か,度の十進数で入れて[座標計算]ボタンをおす.
5.
人工衛星のGPS(全地球測位システム)から座標を読み込むことができる.動作確認はCSI Wireless社のminiMAX(http://www.gisup.com/product/pr_csi_minimax.htm)をUSB-RS232C変換ケーブル(IOデータ,USB-RSAQ2)経由でパソコン(東芝,ダイナブックSS S8)に接続して行っているが,NMEA0183対応のGPSなら接続できる可能性が高い.
a.GPSの電源を入れ,衛星を捕捉していることを確認する(USB-RSAQ2の場合はまだパソコンに接続しない)
b.[経緯度電卓]をクリック
c.初期設定として (1)[comポート]にRS-232Cを接続したポート番号を設定する(通常は1か2,USB接続では4も). (2)座標系の原点を設定する(世界測地系のみ). (3) [Bcon freq]は中波ビーコン(海上交通用)によるDGPSの補正データの局の周波数を設定する.ただし[Bcon freq]を空にしておくと局を自動探索する.もよりの局はCSI Wireless社の世界中のビーコン局のリストhttp://www.csi-wireless.com/support/pdfs/radiolistings.pdfにある.
d.USB-RS232C変換ケーブルをパソコンに接続
e.USB-RS232C変換ケーブルをGPSに接続
f.[GPS off]のボタンをクリックするとGPSからの座標情報が継続的に表示され,平面直角座標やUTM座標に変換して表示される.
[GPS off]ボタンをクリックしたときにmini Max用の初期化コマンドが送られる.GPSを初期化したくないときは,[GPS
off]ボタンをクリックした後でUSB-RS232C変換ケーブルをGPSに接続する.
g.[GPS on]のボタンをクリックすると読み込みが止まる
h.RS-232Cの通信パラメータは,ソフト側ではボーレート9600,8ビット,パリティなし,ストップビット1ビットに設定している.パソコンとGPSの通信がうまくいっているかどうかは,Windows標準添付のハーパーターミナル(アクセサリ,通信)で確認できる.衛星をとらえていないときでも,ふつうはGPSからデータが常に流れている.ハーパーターミナルからGPSにコマンドを送ることもできる.
i.mini MAXの場合,ビーコンで補正しない単独測位でも開けた場所ではHDOPが1.5以下で再現性もあり,現在位置を半径5m内に特定できる.DGPSでは半径1m以下になる.明るい落葉広葉樹林であれば林床でも可能だが,単独測位の精度はHDOP7程度に落ちる.
画像ファイルに出力
2.2 画像ファイルに書き出す
1. ベクトル図形ファイルとラスタ画像ファイルを合成したり,ラスタ画像ファイル同士を合成してWindowsのBMP形式のファイルに書き出す
2. まず[画像ファイルに出力]を選択し,主に表示するファイル(ベクトルかラスタ)と,背景の画像ファイル(ラスタ),書き出す画像ファイル(Windowsビットマップ)を選択する.背景画像は省略可.
3. [ファイル読込]をクリックすると属性変数を読み込んでリストされる.
4. 表示色の赤,青,緑に対応する変数を選ぶ.ベクトル図形ファイルでは図形の重ね順を指定する変数も選べる.
5. 書き出す画像の範囲と解像度を指定する.[縮尺]は紙への印刷時の縮尺を指定する.WindowsのBMP形式のファイルは印刷紙上でのサイズを指定する情報を持っているので,写真レタッチソフトで正確な縮尺に印刷できる.
6. 画像ファイルを表示する場合は,解像度をもとの画像とあわせないと画像が劣化する可能性がある.
7. [色の輝度は絶対値]をチェックしない場合は,色ごとに50-255の間にスケーリングされる.また普通は値の大きなところで輝度が大きい(明るい)が,[濃淡を反転]をチェックすると逆になる.
8. [線の太さ]は図形ファイルでの図形の縁の太さを指定する.これがゼロになるとpolygonやareaは表示できるが,pointやline,treeなどは表示できない.
9. [地の色]は背景も主たる表示ファイルもない部分の色を指定
10. [polygonは輪郭]をチェックすると図形ファイルは輪郭だけが描画される
11. [透過]では表示ファイルと背景ファイルが透過OHPのように合成される.図形ファイルの図形の重なりも同様になる.チェックをはずすと主たる表示ファイルが背景の上に上書きされる
12. [画像をCSV保存]では,合成した画像をラスタファイルとして保存できる.属性変数名はred,green,blue.ファイル名は*.bmp.csvで,*.bmpの部分は指定した画像ファイル名.このラスタファイルを背景画像に使うことで,より多くの情報を自由に重ねて表示できる.
13. 図の凡例は,Excelやエディタなどを使って図形ファイルにpolygonやlineを手書きしてつくる.Excelの連続コピー機能をつかって連続した属性値をもつpolygonを多数作成するとグラデーションによる凡例も簡単にできる.文字はBMPファイルができあがってから写真レタッチソフトで入れる.
14. 色を自由にコントロールするには,[属性値の計算とファイル統合]→[ベクトル属性変数の演算]や[ラスタ変数の統合と演算]でred, green, blueの3原色の輝度を指定する変数を作成する.輝度値を0から255までの値にしておいて,[色の輝度は絶対値]をチェックすれば指定した色が正確に表示できる.RGB値の色見本はPhotoshop LEなどの色パレットを参照.
15. 最後に完成した画像が表示されるが,これは画面のpixelサイズにあわせているので印刷時のサイズとは異なる.縮尺を正確に印刷するにはPhotoshop LEなどを利用する.
|
|
|
|
|
|
VectorSample.csv 透過モード |
RaterSmple.csv |
不透過モードでのベクトルとラスタの 合成出力 |
いったんbmp.csvファイルに出力したあとラスタ演算で合成 |




図2.2 標準添付されているデータの画像出力例.多角形(polygon),穴の空いた多角形(area),折線(line),折線がつながった樹様体(tree),点(point)がラスタ画像データ(色の付いた格子模様)と重ねて表示されている.写真や地図画像も細かなチェック模様(ラスタ)であり,カラー画像は赤(red),緑(green),青(blue)の3原色の光の強さで表現する.
データ入力編集・空の図形の発生
<データ入力・編集>
2.3.1 地図や空中写真の画像のとりこみ
1. 写真や地図画像をラスタデータとして座標上にマッピングする.
2. スキャナなどを使って地図や空中写真の画像を取り込み,必ずフルカラー(24bit)のWindows版BMP形式(Windowsビットマップ)で保存する.白黒や8bitの256色などの画像は不可.「24bitのBMP」であってもソフトによって微妙にフォーマットが異なる.マイクロソフト以外のソフトで画像を操作すると"ファイルがBMPではありません"や"24bit色のBMPファイルではありません"などのメッセージが出るが,Windows付属の「ペイント」でいったん読み込んで24bitのBMPで上書きする.
多数の直交座標点(平面直角座標やUTM,自分の調査地座標など)で位置あわせするとき
3. 「みんなでGIS」を立ち上げて,メニューから[データ入力編集・空の図形の発生]→[BMP画像ファイル→ラスタファイル]のうちで[多数の直交座標で位置指定]を選ぶ
4. 読み込む画像のBMPファイル名と,保存先のラスタファイル名を指定し,[ファイル読込]をクリック
5. 画像が表示される.画面に入りきらない場合は[表示倍率]に縮小率を入れて[拡大縮小]をクリック
6. 遠近のない画像(地図など)と,遠近のある画像(斜めに写した写真など)のどちらかを選択する.前者では左右変倍率のコピー機で斜めにゆがんだ画像も修正できて高速である.後者では3次元のコントロールポイントからカメラ位置の3次元座標を計算して,ある高さzの平面の上の画像を,真上から見た状態で取り込む.レンズの投影方法はフィルム面が平面のピンホールカメラを想定している.処理時間は450MHzのCPUで約10分程度がかかる.航空写真の場合は,本来は[斜め写真]が望ましいが,ふつうは[地図など]でも十分な結果が得られるようだ.
7. 座標が既知の地点をコントロールポイントとして設定する.画像の上でコントロールポイントをクリックし,その座標値を左のテキストボックスに入れ,[地点を登録]をクリック.登録内容のファイル保存や再読込み,削除などもできる.
8. 任意の場所を拡大するには[画像中心を移動へ]をクリックして画像移動モードに移ったあと,中心に表示したい部分をクリックすると画面の中心に移動して表示される.このあと表示縮尺を調節すると,その地点を中心としたまま拡大・縮小される.画像移動モードから図形入力モードに戻るには同じボタンの[図形入力へ]をクリックする.
9. コントロールポイントは[地図など]では最低3地点以上必要で,[斜め写真]では5点以上必要.しかも一列の線上に並ばないように,なるべく互いの距離が離れるように配置する.全ての3点の組み合わせによる3角形を使ってパラメータを決めるので,いたずらに点数を増やすよりも,きれいな三角形が得られるようにコントロールポイントを配置する方が得策.
10. コントロールポイントの設定が終わったら[変換式決定]で画面座標と実座標の変換式を求める.画像の中に正確なベンチマークがあれば通常は誤差は5pixel以内であるが,自然の地形をコントロールポイントにとった[斜め写真]の場合は誤差が数十pixelになることが多い.誤差がこれ以上大きい場合は,コントロールポイントの位置や座標値を再確認した方がよいかも知れない.なお[斜め写真]の場合はBmpLoad.log.csvファイルに誤差とカメラ座標,各コントロールポイントの実座標と,実際の画面上の位置,推定された画面上の位置を保存するので,大きな誤差をもたらしているコントロールポイントを確認できる.なお,[斜め写真]ではコントロールポイント群の重心を中心に,コントロールポイントが存在する範囲の約1.2倍(45度の画角相当)の範囲で写真撮影位置を探索する.
11. 精度が高いはずなのにコントロールポイントの位置などによって誤差が100pixelを超えるようなことが起きる.このような場合は「ゆらぎ」チェックボックスをチェックすると良い.ただし座標値の精度は高くない.
12. 読み込む範囲と画素(pixel)の大きさを実座標で指定して[変換実行].このとき[外側]を選択すると,もとの画像のデータを全て含む領域が取り込まれ,もとの画像に含まれていない部分は欠損値となる.[内側]を選択すると欠損値が入らない小さな領域になる.画素サイズには計算値が入るが,その後の処理のために切りの良い数値に変更しても良い.
13. 取り込むときには,見た目そのままが良ければ[平均]が,植生判別などなるべくもとの画素の色データがほしい場合は[間引]が良いかもしれない.
14. CDなどで配布される1:2万5千や1:5万地形図画像は画素数が多いためそのままではメモリー不足になるので1/2解像度(2万5千分の一地形図は5m程度,5万分の一地形図は10m程度のpixelサイズ)で読み込む.
15. 上記とは別に,普通の写真を画像処理のためpixelの座標系で取り込むには矢印横の[直接]をクリックすると1画素1mとして座標変換式が作成される.
画像の四隅の緯度・傾度がわかっている場合
16. [地図の四隅の経緯度を指定]の方を使う.
17. 四隅の緯度経度を,左下,左上,右上,右下の順に指定する.
18. たとえば,多面体図法で四隅の日本測地系緯度経度がわかっている地図(昔の1:5万地形図)を,世界測地系の平面直角座標のGISファイルに読み込むには,(1)四隅の緯度経度をあらかじめ世界測地系の経緯度に変換しておく(国土地理院のwebサイトなどで可能),(2)このプログラムでの座標系の指定は「世界測地系」の「平面直角座標の最寄りの座標系」とする.
|
|
もとの画像
[外側]の領域で読み込んだ画像.
|
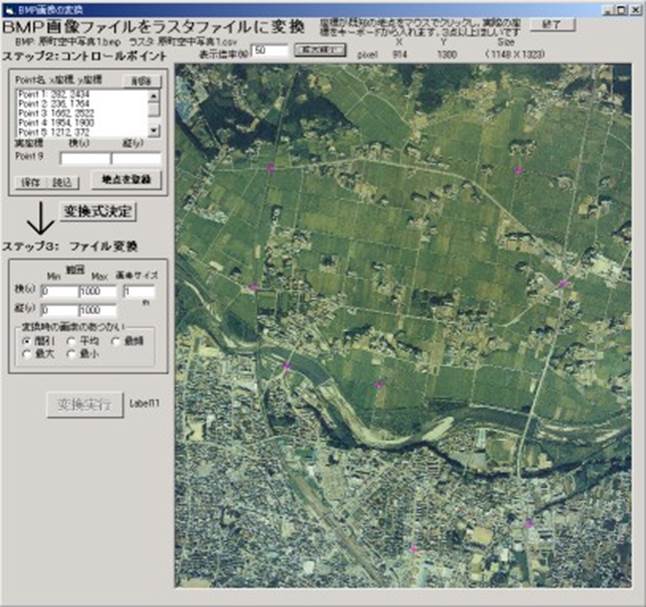
図2.3 画像入力フォーム(左)と読み込む領域の指定(右).空中写真の上の紫色の点はコントロールポイント
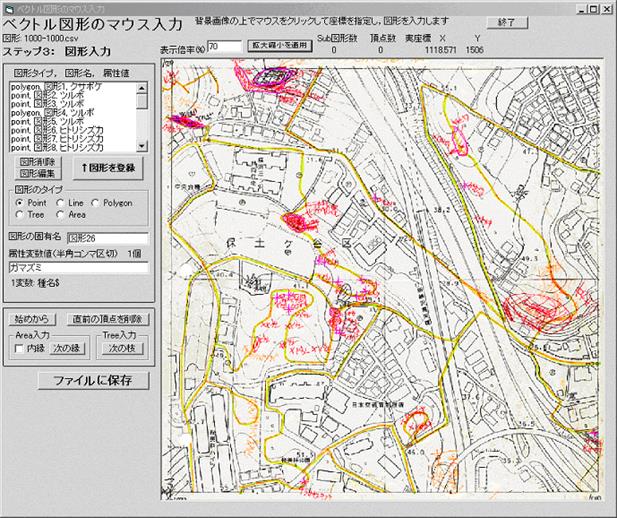
2.3.2 地図や写真上の地点や領域などをマウス入力
1. 地図や写真をラスタファイルに読み込む(前項参照)
2. [データ入力編集・空の図形発生]→[ラスタ画像上にベクトル入力]を選択
3. データを入れるベクトルファイルと背景の画像ファイル(「みんなでGIS」のラスタファイル)を指定して[ファイル名確定].背景用の画像ファイルにはred, green, blueの3つの属性変数名が入っていなければならない.ファイル名を指定しない場合は白紙の上での編集・入力となる.ベクトルファイルやred, green, blueの3つの属性変数名が入っていないラスタファイルを背景画像に使うときは,背景のファイルを[画像ファイルに出力]からいったん画像出力し,その際に[画像をcsv保存]チェックボックスをチェックして,「出力画像名.bmp.csv」というファイル名のラスタファイルを作成し,これを背景画像ファイルとして使う.
4. ベクトルファイルが読まれて,既存のデータがあれば属性変数名が表示される.
5. 図形入力時に同時に入力する属性変数名を指定する.既存の属性データがあるばあい,既存の変数を削除すればファイルからも取り除かれ,また新しい変数を追加することもできる.
6. [マウス入力へ]をクリックすると,新しいフォームが開いて背景画像が表示される.マウスで図形を入力できる空間は表示された背景画像の範囲となる.
7. 背景画像の表示される部分を変えるには[画像中心を移動へ]をクリックして画像移動モードに移ったあと,画像の中心に表示したい部分をクリックすると画面の中心に表示される.このあと表示縮尺を調節すると,その地点を中心としたまま拡大・縮小される.画像移動モードから図形入力モードに戻るには同じボタンの[図形入力へ]をクリックする.
8. 図形入力の流れは,(a)図形のタイプを指定,(b)マウスをクリックして図形入力,(c)画面左のテキストボックスに属性変数値を半角コンマ区切りで入力,(d)[図形を登録]
9. 直前の頂点を取り消すには[直前の頂点を削除].入力中の図形の全取り消しや図形タイプの変更には[始めから].polygonやlineの最初に入力したノードを削除するには,いったん図形を登録し[複写逆]でノード順を逆にした新図形を作成してから削除する.
10. polygonの最後の辺は[図形を登録]によって自動的に閉じられる.
11. areaでは(a)図形のタイプを指定,(b)マウスで単polygonを入力,(c) 次のpolygonを入力するときに[次の縁]をクリック,(d)これから入れるpolygonが[内縁]か外縁かを指定,(e)次のpolygon入力,(f)終わったら[図形を登録]
12. treeでは(a)図形のタイプを指定,(b)マウスで折れ線lineを入力,(c) 次のlineを入力するときに[次の縁]をクリック,(d)次に画像上でクリックすると最近接のノードに接続する,(e)終わったら[図形を登録].川の下流から上流へ,また主流から支流の順に入力する(根本から枝先へ,幹から枝へ).支流の分岐点はあらかじめ必ずノードにしておく.
13. 登録済みの図形を削除するには,リストをクリックして図形を選択した上で[削除]
14. 登録済みの図形を編集するには,リストをクリックして図形を選択した上で[編集].リストをダブルクリックしても同じ.ただしリストからは削除されているので注意.
15. 登録済みの図形をコピーして,同じ形の図形に別の属性値を与える場合は[複写]
16. 適当に図形がたまったら[ファイルに保存].終了時も明示的に[ファイルに保存]しなければ,データは失われる.
17.
GPS(全地球測位システム)から野外で座標を読み込むことができる.GPSで指定した座標上の点でマウスを1回クリックしたのと同等の動作となるので,point入力であれば地点が指定され,lineやpolygonであればノードが追加される.動作確認はCSI Wireless社のmini MAX(http://www.gisup.com/product/pr_csi_minimax.htm)をUSB-RS232C変換ケーブル(IOデータ,USB-RSAQ2)経由でパソコン(東芝,ダイナブックSS S8)に接続して行っているが,NMEA0183対応のGPSなら接続できる可能性が高い.
a.GPSの電源を入れ,衛星を捕捉していることを確認する(USB-RSAQ2の場合はまだパソコンに接続しない)
b.上記と同じように背景画像(1/25000地形図,1/2500都市計画図,航空写真など)を指定して,ベクトル図形を入力できる状態にする.座標系は平面直角座標でもUTMでもよいが,必ず世界測地系にしておく.日本測地系の地図しかない場合は,目印になる地点(道路の交差点など)でGPSと[経緯度電卓]を使って座標を調べ,[かたち情報補変換と計算]で座標軸を平行移動しても,数キロメートル程度以内の狭い範囲の地図であれば問題なさそうだ.まったく背景画像がない場合は[ラスタデータ作成]などで測量する座標範囲の空のラスタデータなどを作成し,画像出力でbmp.csvファイルを出力して,これを背景画像とする.
c.初期設定として (1)[comポート]にRS-232Cを接続したポート番号を設定する(通常は1か2,USB接続では4も). (2)座標系の原点を設定する(世界測地系のみ). (3) [Bcon freq]は中波ビーコン(海上交通用)によるDGPSの補正データの局の周波数を設定する.ただし[Bcon freq]を空にしておくと局を自動探索する.もよりの局はCSI Wireless社の世界のビーコン局リストhttp://www.csi-wireless.com/support/pdfs/radiolistings.pdfにある.
d.USB-RS232C変換ケーブルのUSB側をパソコンに接続
e.USB-RS232C変換ケーブルのRS-232C側をGPSに接続(USB-RSAQ2ではこの順番を変えると動かない)
f.[座標指示]のボタンをクリックするとGPSからの座標情報がひとつ取り込まれ,その地点でマウスをクリックしたのと同じ動作が行われる.pointの場合は地図上に点が表示され,lineやpolygonではノードがひとつ追加される.
g.[連続入力]のボタンをクリックすると,指定した時間間隔で連続してGPSからの座標情報が取り込まれ,そのときの座標地点でマウスをクリックしたのと同じ動作が行われ続ける.pointの場合は地図上の点が移動し,lineやpolygonではノードが追加されてゆく.[連続入力中]をクリックするとGPSからの入力が終わる.
h.RS-232Cの通信パラメータは,ソフト側ではボーレート9600,8ビット,パリティなし,ストップビット1ビットに設定している.パソコンとGPSの通信がうまくいっているかどうかは,Windows標準添付のハーパーターミナル(アクセサリ,通信)で確認できる.衛星をとらえていないときでも,ふつうはGPSからデータが常に流れている.ハーパーターミナルからGPSにコマンドを送ることもできる.
i.[座標指示]や[連続入力]のボタンをクリックしたときにmini Max用の初期化コマンドが送られる.GPSを初期化したくないときは,ボタンをクリックした後でUSB-RS232C変換ケーブルをGPSに接続する.
j.mini MAXの場合,ビーコンで補正しない単独測位でも開けた場所ではHDOPが1.5以下で再現性もあり,現在位置を半径5m内に特定できる.DGPSでは半径1m以下になる.明るい落葉広葉樹林であれば林床でも可能だが,単独測位の精度はHDOP7程度に落ちる.
|
図2.4 図形のマウス入力.右の画像上の紫色の図形は入力済みで,水色は入力中の図形. |
|
2.3.3 GPSなどの緯度経度の地点データの一括読み込み
1. 野外でGPSなどで記録した緯度・経度の地点座標データを,一括して平面直角座標やUTM座標に変換し,「みんなでGIS」のベクトルファイルにする. GPSのNMEAフォーマットの受信ログの一括読み込みのためのものではないが,Excelなどでログをソーティングして$GPGAA行だけ集め,緯度・経度のフォーマットを整形して(度と分の間にコンマを入れる),先頭行に変数名を書き込めば読み込み可能.
2. なお緯度経度でなく地域メッシュを利用した調査データの一括読み込みは,市販・公共データについての「標準地域メッシュ旧テキスト(csv)の読込」機能で読むことができる.
3. 変換元は先頭の行に変数名をつけたCSVファイルとする.緯度経度座標以外の任意の測定データなどが入っていても良い.
4. 緯度や経度を度・分・秒で記録している場合(33度10分12.5秒など)は,それぞれ別の変数とする.緯度と経度で合計6個の変数ができる.ただし10進数で小数点を使って記録している場合(33.17014度など)は,分や秒の変数を用意する必要はない.
5. [データ入力編集・空の図形の発生]→[地点の経緯度を一括変換]
・入出力ファイル名を指定
・緯度や経度を保存している変数名を選択
・座標系と原点を選択
・変換を実行する
6. 座標は日本測地系と世界測地系を選択できる.
日本測地系の経緯度 → 日本測地系の平面直角座標か,ベッセル楕円体のUTM
世界測地系の経緯度 → 世界測地系の平面直角座標か,GRS80楕円体のUTM
日本測地系の経緯度によるファイルを世界測地系の平面直角座標のファイルにすることはできない.
7. name$という変数をつくっておくと,これが図形名につかわれる.
8. 野外での探索経路など,pointをつないでlineをつくるときには,あらかじめ「PointOrder」という変数名で結ぶpointの順番(歩いた順番)を指定しておく.
・[データ入力編集・空の図形の発生]→[地点の経緯度を一括変換]でpointに
・[かたちの情報の変換と計算]→[ベクトル図形のタイプ変更]でpoint列をlineに変換
・lineが複数ある時は,適当にlineの番号をつけて初めのファイルに保存しておき,[ベクトル図形のタイプ変更]のIF条件でline番号を指定しながらひとつづつlineをつくる.
9. GPSでpoligonの外縁の座標を調べた場合にも,あらかじめlineごとに「PointOrder」という変数名で,結ぶpointの順番(歩いた順番)を指定しておく.
・[データ入力編集・空の図形の発生]→[地点の経緯度を一括変換]でpointに
・[かたちの情報の変換と計算]→[ベクトル図形のタイプ変更]でpoint列をlineに変換.その後lineの端点を結んでpolygonをつくる.
・polygonが複数ある時は,適当にpolygonの番号をつけて初めのファイルに保存しておき,[ベクトル図形のタイプ変更]のIF条件でpolygon番号を指定しながらひとつずつlineをつくる.lineをpolygon化する作業は一括で行える.
|
Name$ |
線番号 |
PointOrder |
緯度-度 |
緯度-分 |
緯度-秒 |
経度-度 |
経度-分 |
経度-秒 |
胸高直径 |
雌雄 |
|
p1 |
1 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
23 |
0 |
|
p2 |
1 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
33 |
0 |
|
p3 |
1 |
3 |
30 |
21 |
32 |
130 |
23 |
15 |
29 |
0 |
|
p4 |
1 |
4 |
30 |
21 |
28 |
130 |
23 |
16 |
44 |
1 |
|
p5 |
1 |
5 |
30 |
21 |
12 |
130 |
23 |
19 |
38 |
0 |
|
p6 |
1 |
6 |
30 |
21 |
7 |
130 |
23 |
25 |
35 |
1 |
|
p7 |
1 |
7 |
30 |
21 |
5 |
130 |
23 |
40 |
13 |
0 |
|
p8 |
1 |
8 |
30 |
21 |
23 |
130 |
24 |
4 |
22 |
1 |
|
q1 |
2 |
1 |
30.38167 |
0 |
0 |
130.3844 |
0 |
0 |
40 |
1 |
|
q2 |
2 |
2 |
30.3775 |
0 |
0 |
130.3844 |
0 |
0 |
41 |
1 |
|
q3 |
2 |
3 |
30.37444 |
0 |
0 |
130.3839 |
0 |
0 |
18 |
0 |
|
q4 |
2 |
4 |
30.37194 |
0 |
0 |
130.3914 |
0 |
0 |
43 |
1 |
|
q5 |
2 |
5 |
30.37083 |
0 |
0 |
130.4003 |
0 |
0 |
29 |
0 |
図2.5 入力用の外部ファイルの例.コンマ区切りのテキストファイルにする.この中で必須な変数は緯度と経度の「度」のふたつ.
2.3.4 プローブ用のデータ発生
1. GISではプローブ用の格子状のpointや正方形polygon,空の画像などを頻繁に使う.
2. 空のラスタデータを発生させるには[データ入力編集・空の図形の発生]→[ラスタデータ作成].ラスタデータの空間範囲と解像度を設定し,ファイル名を設定して[実行].空間範囲はセルの外側の縁の座標を設定する.
3. 格子状に配置された多数のpoint図形を発生させるには[データ入力編集・空の図形の発生]→[格子点pointデータ作成].データの空間範囲と解像度を設定し,ファイル名を設定して[実行].空間範囲はいちばん外側のpointの位置なので,ラスタのセルとあわせる場合には注意が必要.
4. ランダムに配置された多数のpoint図形を発生させるには[データ入力編集・空の図形の発生]→[ランダムpointデータ作成].データの空間範囲と点数を設定し,ファイル名を設定して[実行].ランダムな点は統計的な検定などに使う.
5. 格子状の長方形polygonを発生させるには[データ入力編集・空の図形の発生]→[長方形グリッドのpolygonデータ作成].データの空間範囲と解像度を設定し,ファイル名を設定して[実行].空間範囲はラスタデータの場合と同じ.
6. 円をひとつつくるには[円形の多角形をひとつ作成]を選択する.多角形で円を表示するので,精度として多角形の辺の長さか,その辺に対応する中心角のどちらかを指定する.精度を細かくするときれいな円になるが,その後の取り回しは面倒になる.
|
|
|
|
|
4角形のpolygonでタイル状に埋められたpolygon格子.ラスタファイルのセルも同様 |
格子点にpointがならぶpoint格子.外縁は指定した範囲. |
ランダムな点.外縁は指定した範囲.統計的な検定などに使用する. |


図2.6 新しい図形の発生.ラスタファイルのセルの中心や,polygon格子の各polygonの中心にpoint格子を配置するには,セルの大きさの半分だけ位置をずらす必要がある.
2.3.5 投影方法を変更しながら画像読込(古い5万分の一地形図など)
明治時代につくられた5万分の一地形図などは,鉄道の物流と生糸の国際的な輸出による大きな社会変革の前の日本の自然の姿を表している重要な資料であり,現在の生物の分布には当時の土地利用の影響も残っている.しかし現在使われている横メルカトル法と違って多面体図法なのでうまくGISに取り込めないこともあるので,簡単なプログラムを作成した.地図の4隅の緯度経度を入力し,平面直角座標やUTMの座標を持ったpoint格子として出力する.UTM座標の2万5千分の1地形図画像を平面直角座標で読み込むなど,投影法が違う地形図の読み込みにも使える.
1. 古地図等はスキャナ入力してRGB24ビットのBMPフォーマットの画像ファイルにしておく.画像には緯度経度がわかる4隅が含まれている必要がある.
2. 地図の四隅の緯度と経度を求めておく.必要に応じて日本測地系と世界測地系の変換を行っておく.この4点間を線形に補間するが,長方形でなくても任意の4角形でよい.
3. [データ入力編集・空の図形の発生]→[古地図読込]を選択
4. 画像ファイル名とpoint格子のデータを出力するファイル名を指定.また変換先の座標系を指定して[ファイル読み込み].
5. 背景画像の表示される部分を変えるには[画像中心を移動へ]をクリックして画像移動モードに移ったあと,画像の中心に表示したい部分をクリックすると画面の中心に表示される.画像移動モードから図形入力モードに戻るには同じボタンの[図形入力へ]をクリックする.
6. 表示された地図の4隅を「左下」,「左上」,「右上」「右下」の順にクリックして,各地点の経度と緯度(新しいもの)を10進数で入力して[地点を登録].平面直角座標やUTMでなく緯度経度であることに注意.古い地図は全て日本測地系であるので,日本測地系の緯度・経度から世界測地系の緯度・経度への変換は国土地理院のホームページなどで行う.
7. [変換実行]でpoint格子のベクトルファイルに書き込まれる
8.
このあと普通の画像データであるラスタ・ファイルに変換するには,
(1)返還後の座標系での図郭の範囲を確認
(2)必要な図郭と解像度を持った空のラスタ・ファイルを作成,
(3)[point属性を補間してラスタに]にで変換,の手順を取る.
はじめにpointとして読み込むときには小さめの画素としておき,それに比べて大きめの画素のラスタ・ファイルにデータを写すとよい.このときの[point属性を補間してラスタに]のオプションは[欠損データは欠損値のまま],[重複データは平均]が早くてきれい.
<市販・公共データの読込>
2.4.1 標準地域メッシュ旧テキスト(csv)の読込
1. 国土数値情報の中の「旧 統一フォーマット形式,テキスト」の中で標準地域メッシュを利用したデータを読み込む(https://nlftp.mlit.go.jp/ksj/old/old_datalist.html).先頭行に変数名がつき,メッシュ番号が変数として入っていれば手作業で入力したデータも読み込むことができる.第3次メッシュの1/2や1/4などの分割地域メッシュに対応.
2. 上記サイトからダウンロードしzipファイルから取り出しておく.必要に応じて文字コードをShift JISに変更しておく.メッシュコードは区切りを入れず数字だけの列にしておく.
3. 操作は,[データ入力編集]から[国土数値情報 旧テキスト メッシュ]を選択
4. もとのデータは緯度・経度の座標系だが,読み込んだデータは平面直交座標系(都市計画図の座標など)やUTMに変換され,「みんなでGIS」のpoint(メッシュ中心点)かpolygonのタイル(メッシュ)に保存される.
5. 座標変換のために,日本の都市計画図の19座標系(平面直角座標)では第1系から第19系まで,またはUTM座標系ではUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく(都市計画図とUTM座標では原点とともに若干のパラメータが違う.精度は日本の19座標系の方が高い).調査対象地域が座標系の境界にある場合には,どちらか一方の原点を選ぶか,自分の調査地域の中心付近に任意の原点を置いても良い.この場合の計算では19座標系のパラメータが使われる.旧来の日本測地系TKYと新しい世界測地系JGDを選択する.
6. [読込実行]で読み込む.できたファイルのコメント行には座標系情報や元のファイル名などが書き込んである.
7. 必要に応じて「point属性を補間してラスタに」変換でラスタ化する.
2.4.2 XMLファイル(GML)の標高データや土地利用データの読込
8.
GMLによるXMLで記述された国土地理院の10mメッシュ標高データ
(https://fgd.gsi.go.jp/download/menu.php)や国土交通省の100mメッシュ土地利用データ
(https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-L03-b.html)を読み込む. なお.xmlの拡張子がついたファイルはテキストなので,対象範囲や解像度の数値を目で読んでWordやExcelを使って手作業で読み込むこともできる.
9. 上記サイトからダウンロードしzipファイルから取り出しておく.メタファイルと本体が両方あるが,ファイル名にMETAとついていないのが本体.文字コードはUTF-8であり国土地理院のように日本語文字を含むファイルは文字化けするため,あらかじめShift JISに変更しておく.
10. 操作は,[データ入力編集]から[地形・土地利用XMLメッシュデータ(GML)]を選択
11. もとのデータは緯度・経度の座標系だが,読み込んだデータは平面直交座標系(都市計画図の座標など)やUTMに変換され,「みんなでGIS」のラスターファイル,point格子,方形polygonのタイル(あまり実用的でない)に保存される.
12. 座標変換のために,日本の都市計画図の19座標系(平面直角座標)では第1系から第19系まで,またはUTM座標系ではUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく(都市計画図とUTM座標では原点とともに若干のパラメータが違う.精度は日本の19座標系の方が高い).調査対象地域が座標系の境界にある場合には,どちらか一方の原点を選ぶか,自分の調査地域の中心付近に任意の原点を置いても良い.この場合の計算では19座標系のパラメータが使われる.旧来の日本測地系TKYと新しい世界測地系JGDを選択する.
13. [読込実行]で読み込む.できたファイルのコメント行にはXMLファイルの対象範囲指定などがそのまま書き込んである.
14.
土地利用はコードで保存されるため,CodeSpace=LandUseCd-09.htmlにより「LandUseCd-09.html」をネットで見て対応を確認する.
https://nlftp.mlit.go.jp/ksj/gml/codelist/LandUseCd-09.html
15. 土地利用はコードを数値で保存すると色の濃淡としてそのまま表示できる.コードの文字列として保存すると「一定の距離の属性を集計して図形に」の機能により指定距離内の土地利用の頻度を集計できる.
2.4.3 50mメッシュ標高データ「数値地図50mメッシュ(標高)」の読込
16. 日本全国の約50mメッシュの標高地形データは,国土地理院の地図の販売店から日本全体を3地域に分けたCD-ROMデータを購入できる(CD1枚が7500円,http://www.jmc.or.jp/).2次メッシュ(国土地理院の2万5千分の1地形図に相当)をひとつのファイルにして,これを縦横200個ずつに区切ったメッシュの中心点の標高データが保存されている.これは東西2.25秒間隔,南北1.5秒間隔に相当し,東京あたりでは約55m×45mになる.
17. 操作は,[データ入力編集]から[国土地理院「数値地図50mメッシュ(標高)」]を選択
18. CD-ROMのドライブを選択すれば,CD内の2万5千分の1の地形図名と2次メッシュコードの対応表が表示されるはずである.この2次メッシュがひとつのファイルになるが,島嶼や海岸ではうまく地図に収まるようにアレンジしてあるので,このような場所では2次メッシュと2万5千分の1地形図名は必ずしも1対1に対応しない.
19. 読み込むファイルを,2次メッシュ・コード地図名のリストからクリックして選択するか,あるいはひとつの地点の座標を緯度・経度で与えて,その地点を含むファイルを求めることもできる.
20. もとのデータは緯度・経度の座標系だが,読み込んだデータは平面直交座標系(都市計画図の座標など)に変換され,「みんなでGIS」のベクトルファイルにpointの属性として保存される.
21. 座標変換のために,日本の都市計画図の19座標系(平面直角座標)では第1系から第19系まで,またはUTM座標系ではUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく(都市計画図とUTM座標では原点とともに若干のパラメータが違う.精度は日本の19座標系の方が高い).調査対象地域が座標系の境界にある場合には,どちらか一方の原点を選ぶか,自分の調査地域の中心付近に任意の原点を置いても良い.この場合の計算では19座標系のパラメータが使われる.
22. [読込実行]で読み込む.標高の変数名はDEMで単位はmである.できたファイルのコメント行には2次メッシュの4隅のxy座標を書き込んである.
23. 地形の傾斜や凸凹などを計算するにはラスタファイルに変換する必要がある.もとの緯度経度座標では等間隔であるが,xy座標に変換すると等間隔ではなくなるので補間が必要である.このような標高データをDEM (Digital Elevation Model)とよぶことも多い.
24. このためにまず,[データ入力編集・空の図形の発生]→[ラスタデータ作成]でxy座標での空のメッシュを作成しておく.座標の範囲には,コメント行の座標値を参考にする.次に[かたち情報の変換と計算]→[point属性を補間してラスタに]で欠損データを補間(2次微分最小化)しながらラスタに変換する.
25. 世界測地系になってからの新しいフォーマットのCDでは,座標は日本測地系と世界測地系を選択できる.それ以前のものでは日本測地系のみとなる.
|
vector |
|||||
|
国土地理院「数値地図50mメッシュ(標高)」 453043.MEM 左下x=-60088.823883418 y=-295519.362487666 左上x=-60037.8738697522 y=-286278.926177965 右下x=-48070.8896995188 y=-295578.950805483 右上x=-48030.1307069342 y=-286338.611893157 |
|||||
|
DEM |
type$ |
name$ |
NodeNum |
x1 |
y1 |
|
0 |
point |
453043x1y1 |
1 |
-60058.65173 |
-295496.4269 |
|
0 |
point |
453043x2y1 |
1 |
-59998.56186 |
-295496.7576 |
|
以下省略 |
|||||
図2.7 50mメッシュ標高データを読み込んだpoint格子のベクトルファイルの例.屋久島の永田岳周辺でメッシュコードは4530-43.座標系は都市計画図の第2系.コメント行が長いので,ここでは見かけ上3行だがファイル内では1行になっている.
2.4.4 10mメッシュ標高データ「GISMAP Terrain」の読込
1. 国土地理院の2万5千分の1地形図の測量結果をもとにつくられた約10mメッシュの標高地形データが,北海道地図(株)からGISMAP Terrainとして販売されている(http://www.hcc.co.jp/).2次メッシュ(国土地理院の2万5千分の1地形図に相当)をひとつのファイルにして(値段はファイルひとつで数万円),これを縦横1000個づつに区切ったメッシュの中心点の標高データが保存されている.これは東西0.45秒間隔,南北0.3秒間隔に相当し,東京あたりでは約11m×9mになる.このような標高データをDEM (Digital Elevation Model)とよぶことも多い.
2. 操作は,[データ入力編集・空の図形の発生]→[北海道地図 GISMAP Terrain 10mメッシュ標高]を選択
3. ファイルのあるディレクトリを選択する.「2次メッシュコード.dem.hgf」という名前のファイルが表示されるので,このファイルを選択する.hgfフォーマットはファイル内に2次メッシュの情報がないためファイル名から座標を決めるので,ファイル名は正確でなければならない.ここではファイル名に必ず「.dem」という文字列が入っている必要がある(特に2次メッシュコード)ので,もし「2次メッシュコード. hgf」というファイル名であったなら必ず「2次コード.dem.hgf」にファイル名を変更しておく.
4. もとのデータは緯度・経度の座標系だが,読み込んだデータは平面直交座標系(都市計画図の座標など)に変換され,「みんなでGIS」のベクトルファイルにpointの属性として保存される.
5. 座標変換のために,日本の都市計画図の19座標系では第1系から第19系まで,またはUTM座標系ではUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく(都市計画図とUTM座標では原点とともに若干のパラメータが違う.精度は日本の19座標系の方が高い).調査対象地域が座標系の境界にある場合には,どちらか一方の原点を選ぶか,自分の調査地域の中心付近に任意の原点を置いても良い.この場合の計算では19座標系のパラメータが使われる.
6. [読込実行]で読み込む.標高の変数名はDEMで単位はmである.できたファイルのコメント行には2次メッシュの4隅のxy座標を書き込んである.
7. 地形の傾斜や凸凹などを計算するにはラスタファイルに変換する必要がある.もとの緯度経度座標では等間隔であるが,xy座標に変換すると等間隔ではなくなるので補間が必要である.
8. このためにまず,[データ入力編集]→[ラスタデータ作成]でxy座標での空のメッシュを作成しておく.座標の範囲には,コメント行の座標値を参考にする.
9. 次に[かたち情報の変換と計算]→[point属性を補間してラスタに]で欠損データを補間(2次微分最小化)しながらラスタに変換する.
10.
座標は日本測地系と世界測地系を選択できる.
日本測地系の経緯度 → 日本測地系の平面直角座標か,ベッセル楕円体のUTM
世界測地系の経緯度 → 世界測地系の平面直角座標か,GRS80楕円体のUTM
日本測地系の経緯度によるファイルを世界測地系の平面直角座標のファイルにすることはできない.
2.4.5 世界30秒メッシュ(約1km)標高データ「GTOPO30」の読込
1. USGSによる世界をカバーした30秒メッシュの標高地形データが,GTOPO30という名前で公開されている.世界中を33個のタイルに分けて別のファイルになっている.空間解像度は東京あたりでは東西730m×南北900mになる.
2.
GTOPO30のデータのあるサイトは以下の通り
http://www1.gsi.go.jp/geowww/globalmap-gsi/gtopo30/gtopo30.html
必要な部分をダウンロードし,ひとつのフォルダに解凍しておく.解凍にはLHUTなどが便利(http://kazusoft.net/lhut32.html).標高データの入ったファイル(.DEM)だけでなくヘッダーファイル(.HDR)も参照する.
3. 操作は,[データ入力編集・空の図形の発生]→[USGSによるGTOPO30世界30秒メッシュ標高データ]を選択
4. ファイルのあるディレクトリを選択する.「ファイル名.DEM」という名前のファイルが表示されるので,このファイルを選択する.
5. もとのデータは世界座標系の緯度・経度だが,読み込んだデータはUTMや平面直交座標系(都市計画図の座標など)に変換され,「みんなでGIS」のベクトルファイルにpointの属性として保存される.
6. 座標変換のために,日本の都市計画図の19座標系の第1系から第19系まで,またはUTM座標系ではUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく.UTMゾーンのリストになくても,赤道上の地点を原点に選んでテキストボックスに入力しておくと任意のゾーンのUTMにできる.
7. データのサイズが大きいので,読み込む範囲を緯度・経度で指定する.
8. [読込実行]で読み込む.標高の変数名はDEMで単位はmである.
9. 地形の傾斜や凸凹などを計算するにはラスタファイルに変換する必要がある.もとの緯度経度座標では等間隔であるが,UTM座標などに変換すると等間隔ではなくなるので補間が必要である.
10. このためにまず,[データ入力編集]→[ラスタデータ作成]でUTM座標などでの空のメッシュを作成しておく.座標の範囲は経緯度電卓などで計算する.
11. 次に[かたち情報の変換と計算]→[point属性を補間してラスタに]で欠損データを補間(2次微分最小化)しながらラスタに変換する.
12. 日本測地系と世界測地系を選択できるようになっているが,GTOPO30は世界座標系なので必ず世界測地系を選択を選択する.
2.4.6 海底も含む世界30秒メッシュ(約1km)標高データ「SRTM 30 Plus」
海底の地形も含めた標高データを得られる.もとのGTOPO30よりもこちらの方が便利かもしれない.
http://topex.ucsd.edu/cgi-bin/get_srtm30.cgi
1.
経度と緯度の範囲を指定して,各地点の以下の内容を含んだテキストファイル(get_srtm30.cgi)をダウンロードする.
経度 緯度 高度
2.
Word, テキストエディタ,Excelなどに読み込んで以下の加工を行う
・コンマ区切りに変更
・ヘッダーとして変数名の「経度, 緯度, 高度」を付ける
3. [地点の経緯度を一括変換]にてGISのファイルに変換する
4. ラスタファイルへの変換は上記のGTOPO30と同じ
2.4.7 1kmメッシュ気候統計値の読込
1. 気象庁の観測と推定による日本全国の約1km四方(3次メッシュ)の気候データは気象業務支援センター(http://www.jmbsc.or.jp/)で販売している「平年値」と呼ばれる1枚のCD-ROMにはいっている(2730円).気温,降水量,積雪深の3つのファイルに分かれて全国のデータがひとつのファイルになっている.なお3次メッシュは東西45秒,南北30秒に相当し,東京あたりでは約1.1km×0.9kmになる.
2. 操作は,[データ入力編集・空の図形の発生]から[気象庁「平年値」1kmメッシュ気候値]を選択
3. CD-ROMのドライブを選択すれば,MTEMP.DAT, MPREC.DAT, MSNOW.DATの3つのファイルが表示されるはずである.
4. 気候要素として,気温と降水量,積雪深のどれかを選ぶ
5. 全国のファイルがひとつになっているので,必要な地域の範囲を緯度と経度で指定する.
6. もとのデータは緯度・経度の座標系だが,読み込んだデータは平面直交座標系(都市計画図の座標など)に変換され,「みんなでGIS」のベクトルファイルに4角形polygonの属性として保存される.気候値は月別のものもあるが全てが保存される.
7. 座標変換のために,日本の都市計画図の19座標系では第1系から第19系まで,またはUTM座標系ではUTMゾーン51から56のうち該当するものをリストからダブルクリックして原点を定めておく(都市計画図とUTM座標では原点とともに若干のパラメータが違う.精度は日本の19座標系の方が高い).調査対象地域が座標系の境界にある場合には,どちらか一方の原点を選ぶか,自分の調査地域の中心付近に任意の原点を置いても良い.この場合の計算では19座標系のパラメータが使われる.
8. [読込実行]で読み込む.
9.
1kmメッシュは,降水量の空間スケールとしては適当だが,気温については1kmメッシュ内でも山岳地域では数百メートルの標高差があるので,あてにならない.そこで,[属性計算]によって50mメッシュ標高データから気候値の1kmメッシュ内の平均標高を求めておき,気温の低下率を100mで0.6℃とすれば,
地点の気温値 = 1kmメッシュの気温値 − 0.006×(地点の標高−1kmメッシュの平均標高)
として地点の気温を計算することもできる.ただし,メッシュ統計値の計算で使用された標高値が必ずしも50mメッシュの標高の平均値でない可能性もある.
10.
座標は日本測地系と世界測地系を選択できる.
日本測地系の経緯度 → 日本測地系の平面直角座標か,ベッセル楕円体のUTM
世界測地系の経緯度 → 世界測地系の平面直角座標か,GRS80楕円体のUTM
日本測地系の経緯度によるファイルを世界測地系の平面直角座標のファイルにすることはできない.
2.4.8 土地利用図「細密数値情報(10mメッシュ土地利用)」の読込
1. 首都圏と中部圏,近畿圏では1970年代から10mメッシュの土地利用図が整備されていて,国土地理院の地図の販売店から各地域の各調査時期ごとのCD-ROMデータを購入できる(CD1枚が9450円,http://www.jmc.or.jp/).カテゴリは山林・荒地等,田,畑・その他の農地,造成中地,空地,工業用地,一般低層住宅地,密集低層住宅地,中・高層住宅地,商業・業務用地,道路用地,公園・緑地等,その他の公共公益施設用地,河川・湖沼等,その他,海であり,生物の環境の解析に利用できる.ひとつのファイルが東西4km,南北3kmであって都市計画図に対応していて,座標系も都市計画図と同じである.
2. この機能は後述のものと似ているが,ファイルごと(4km×3kmの範囲)の読みとりであることが異なる.読み込んだ結果はひとつの変数に格納される.
3. 操作は,[データ入力編集・空の図形の発生]から[国土地理院10mメッシュ土地利用図]を選択
4. CD-ROMの入ったドライブを選択すると,自動的にCD内のファイルコード図が表示されるはずである.
5. (1)図を見てファイルコードからファイル名を生成する,(2)都市計画図の座標値からその地点を含むファイルの名前を生成する,(3)ファイル名を直接指定する,などのいずれかの方法でファイル名を指定する.
6. 作成する「みんなでGIS」のファイルのタイプを指定する.ラスタファイル,point格子,正方形のpolygon格子の3タイプが選べる.正確な解析やカテゴリごとの色の細かな指定にはpolygon格子が適しているが,高速な処理ではラスタファイルが良い.
7. 1から16までのコードを数値として読み込むか,「海」というような名称の文字列をデータとするかを指定できる.通常はコードをそのまま使うのが効率的だと思われる.なお「17対象地域外」以降は欠損値になる.
8. 読込実行をクリックして読み込む.変数名はコード数値のときはLandUseで,文字列の場合はLandUse$になる.
9. 首都圏のデータは都市計画図の座標との対応がとれているが,いまのところ近畿圏と中部圏は手元にCDがないので,たぶん正しいと思うが座標の動作確認はできていない.
10. 世界測地系の「細密数値情報(10mメッシュ土地利用)」にも対応している.世界測地系のものとは図郭が数百メートルずれる.
2.4.9 土地利用図「細密数値情報(10mメッシュ土地利用)」の読込 広域の集計
1.
前述の機能と似ているが,以下の点で異なる
・複数のファイルにわたる広域のデータをいちどに読み込む
・データを受け取るラスタファイルのセルごとに,土地利用分類カテゴリの占める面積を求める.このラスタファイルには19個の新しい変数が追加される.このラスタファイルの座標系は平面直角座標でなければならない.
・読み込む範囲やセルの大きさは,データを受け取るラスタファイルのものが使われる.
2. 首都圏と中部圏,近畿圏では1970年代から10mメッシュの土地利用図が整備されていて,国土地理院の地図の販売店から各地域の各調査時期ごとのCD-ROMデータを購入できる(CD1枚が9450円,http://www.jmc.or.jp/).カテゴリは山林・荒地等,田,畑・その他の農地,造成中地,空地,工業用地,一般低層住宅地,密集低層住宅地,中・高層住宅地,商業・業務用地,道路用地,公園・緑地等,その他の公共公益施設用地,河川・湖沼等,その他,海であり,生物の環境の解析に利用できる.ひとつのファイルが東西4km,南北3kmであって都市計画図に対応していて,座標系も都市計画図と同じ平面直角座標である.
3.
全体の流れは以下のようになる.
・まず空のラスタファイルを用意する
・このファイルにデータを追加する
4. 操作は,[データ入力編集・空の図形の発生]から[国土地理院10mメッシュ土地利用図 広範囲の集計]を選択
5. CD-ROMの入ったドライブを選択する.「ファイルコード.TDU」という名前のファイルがリストされたら,そこが正しいドライブやディレクトリである.
6. 受け取るファイル名を指定する.これは必ず既存のラスタファイルでなければならない.
7. 読込実行をクリックして読み込む.
8. 変数名は「1山林・荒地」などになる.全部で19個の変数ができ,土地利用分類ごとのセル内での面積(m2)が変数に保存されている.
9. ファイルが存在しない場所は「17対象地域外」になる.
10. 今のところ首都圏のデータのみが使用できる.(近畿圏と中部圏は手元にCDがないのでつくっていない)
11. 世界測地系の「細密数値情報(10mメッシュ土地利用)」にも対応している.世界測地系のものとは図郭が数百メートルずれる.
2.4.10 全国植生調査3次メッシュデータ(1kmメッシュ)の読込
環境省が3次メッシュ(約1km×1km)の中心で行った植生調査結果が生物多様性センターからインターネット上で公開されている(http://www.biodic.go.jp/dload/mesh_vg.html).第4回(1988-1992)と第5回(1992-1996)の結果を無料でダウンロードできる.
1. 3次メッシュの中心位置のpointの値として「みんなでGIS」の新しいベクトルファイルに読み込む.
2. 上記のアドレスから「植生調査共通凡例コード等」と必要な時期の「植生3次メッシュデータ」の両方を自分のパソコンのディスクにダウンロードする.
3. LHAの圧縮ファイルなので,適当な解凍ソフトで解凍する.ひとつのディレクトリに凡例ファイルを含めて,全てのファイルを入れておく.veg04_05guide.htmlなどの説明書は重複して入っているので上書きしても良い.解凍ソフトは「窓の杜」http://www.forest.impress.co.jp/などから無料ソフトをダウンロードできる.
4. 「みんなでGIS」を起動し[データ入力・空の図形の発生]→[植生調査3次メッシュデータ]
5. 読み込むファイルの選択で,解凍したディレクトリを選ぶ.veg_gunraku.csvやveg05mesh.csvなどのファイル群が見える.正しく選択すると「データのディレクトリ」と表示される.
6. 植生調査ファイルには全国のデータが入っているが,平面への投影では全国をひとつの座標系で投影できないので,座標範囲を平面直角座標(都市計画図など)かUTM座標で指定する.地図上で緯度経度をよみとって範囲を決めたときには[経緯度電卓]で座標変換できる.
7. 受け取るファイル名を指定する.新しいファイルを作る.
8. 読込実行をクリックして読み込む.
9.
植生のタイプは4つのレベルでtree状に細分化されていて,この情報も属性値として保存されている.
a.区分 気候帯,自然の植生と人手の入った植生,など.(11区分で0-Aまで)
b.集約群落 大まかな分類(群団,群集,クラス). (「区分」内を
10進数2桁で細分)
c.群落 基本的な分類(群集,亜群集). (「集約群落」内を10進数2桁で細分)
d.詳細 群集以下. (「群落」にアルファベットのsuffixをつけて表現)
10. このプログラムでは区分番号,集約群落番号,群落番号,詳細群落番号は全て十進数で表現している.詳細群落番号は小数点以下2桁を使い,Aを.01,Bを.02などと表現する.
11. 属性変数の「自然度」は遷移の極相で大きく,人工的な環境で小さくなる(1-10).詳細はveg_sizendo.csvファイルを参照
2.4.11 数値地図2500(空間データ基盤)の読込
国土地理院のホームページから閲覧目的でダウンロードできるが,日本地図センターでもCD-ROMを市販している.1:2500都市計画図に相当する市区町村界,町丁目,道路,鉄道,河川・池沼,三角点などをベクトルデータとして取得できる.これらはそれぞれ別のファイルになる.
1. インターネットのwwwで国土地理院の「数値地図(空間データ基盤)閲覧(試験公開)」をみる(http://mapbrowse.gsi.go.jp/)
2. このホームページの「閲覧する市区町村の選択」をクリック
3. 必要な市区町村の「数値地図2500」をクリックして,ファイルを自分のパソコンのディスクにダウンロードする.
4. LHAの圧縮ファイルなので,適当な解凍ソフトで,もとのディレクトリを生かして解凍する. 1:2500都市計画図の1枚に相当する範囲がひとつのディレクトリになり,さらにその中に水域や道路などの項目ごとのサブディレクトリができる.解凍ソフトは「窓の杜」http://www.forest.impress.co.jp/などから無料ソフトをダウンロードできる.
5. 「みんなでGIS」を起動し[データ入力・空の図形の発生]→[数値地図2500(空間データ基盤)の読込]
6.
解凍したディレクトリから,必要な1:2500都市計画図のサブディレクトリの中の,さらに必要な項目(道路,水界など)のサブディレクトリを選ぶ..atrや.arcなどの拡張子のファイル群が見える.正しく選択すると[読込実行]ボタンの横に「空間データ基盤のディレクトリ」と表示される.以下は項目のサブディレクトリ名.
gyousei 市区町村,町丁目
gaiku 街区
road 道路
mizu 水域
kijunten 三角点
tatemono 公共の建物
others 鉄道,駅,場地(公園など)
7. 町丁目や水域などはpolygonだが,これをlineとして保存することもできる.lineとして保存すると,polygonが図郭で切られる部分の線や,ドーナツ状の形状を擬似的に表現するための割り込み線など(線種タグ5番以上)が削除される.複数の地図をまとめてpolygonの外縁を表示するには,lineとして読み込んでからファイルを統合するとよい.
8. [読込実行]で読み込む.
9. 水域や道路などがそれぞれ別のファイルになる.図郭も独立したファイルとして作成するが,オプションで[polygonとして保存]を選択すると図郭は長方形のpolygonになり,[lineで保存]を選択すると4本の外縁のlineになる.
10. .atrや.arcなどの拡張子のファイルの名前を変えてはいけない.また違う1:2500都市計画図のファイルを混在させてはいけない.
11. 1:25000地形図相当の「数値地図25000(空間データ基盤)」はフォーマットが全く違うので読めない.今のところ,世界測地系の街区ありのデータで動作確認している.
2.4.12 2万5千分1地形図地図画像「数値地図25000(地図画像)」の読込
<CD-ROM>
1. CD-ROMにふつうの1:2500地形図の画像が入っている.UTM座標系にマッピングしてあるTIFF画像なので,画像をBMPに変換した後で,四隅の座標をコントロールポイントとして指定して読み込むことができる.
2. CD-ROMのドライブのDATAディレクトリを開くと,KANRI.CSVというファイルがあるので,これをダブルクリックしてExcelで開いて見る. 1:2500地形図の地図名とファイル名の対応表が入っている.日本測地系ではKANRI.CSVだが世界測地系はKANRI2.CSVを見る.
3. さらに4桁の数字のディレクトリが見えるが,これはファイル名の先頭4桁に当たる(2次メッシュコード).必要なディレクトリの必要なファイルをPhotoshopLEなどの画像ソフトにドラッグ&ドロップして開く.この画像を24bitカラーのWindowsビットマップ(BMP)ファイルとして,自分の作業フォルダに保存する.
4. KANRI.CSV(あるいはKANRI2.CSV)をExcelで見て,地図の四隅の緯度・経度を確認する.この緯度経度を[経緯度電卓]で平面直角座標にしておく(日本測地系の経緯度か世界測地系かを確認しておく).
5. [データ入力編集・空の図形の発生]→[BMP画像ファイル→ラスタファイル]から,4すみの座標を入力して「みんなでGIS」のラスタファイルに変換する.
6. この地図と同じUTM座標系を使うのが良い.無理に平面直角座標で読み込もうとすると,地図によっては誤差が大きくなる.うまく行かない場合は[古地図読込]からいったんpointデータに変換して,その後に[pointを補間してrasterに]にて画像のrasterファイルを作ると座標は正確になる.ただし高解像度にしようとするとメモリー不足になりやすい.
7. 紙地図的な色にするには[2万5千分の1地形図のCD画像の色を紙地図的に変換]をつかうと便利.
<インターネット>
国土地理院の利用規程では「閲覧目的」に制限されているが,技術的には下記のような操作が可能なので,いつか利用規程の条件がゆるめられれば利用可能になるかもしれない.現在の時点ではインターネットからダウンロードした地図画像を論文や報告書に使うことはできない.
1. インターネットのwebで国土地理院の「地形図閲覧債サービス」をみる(http://mapbrowse.gsi.go.jp/)
2. 必要な地図を表示する.市販の1:25000地形図の1/4の部分が表示される.
3. 表示されたインターネットの地図の,四角と中心付近の目立つ場所の合計5カ所程度にコントロールポイントを選んで,マウスをあわせて左クリック(ふつうのクリック)するとその地点の緯度と経度が表示されるのでこれを記録して[経緯度電卓]でUTM座標か平面直角座標に変換しておく.
4. 自分のディスクに地図画像を保存する.
5. 画像のフォーマットがPNG(Portable Network Graphics)なので,PhotoshopLEなどの写真レタッチソフトで画像ファイルを読み込んで,RGB24ビットカラーのBMPファイルとして保存する.
6. [データ入力編集・空の図形の発生]→[BMP画像ファイル→ラスタファイル]で,上記3番のコントロールポイントを使用して読込む.
2.4.13 2万5千分の1地形図のCD画像の色を紙地図的に変換
日本地図センターで売っている国土地理院の2万5千分の1地形図のCD-ROMの地図画像はデータ指向のため背景地図には向かない.そこで 緑→白,赤→黄色,シアン→青となるような色の変換を行って紙地図のような色にする.[ラスター変数の演算]でも可能だが大きな画像を早く変換できる.
1. あらかじめ[BMP画像入力]などから地図画像を読んでラスタ−ファイルにしておく.
2. [2万5千分の1地形図のCD画像の色変換]を立ち上げ,ラスタ−ファイル名を指定して実行.
3. 元のファイル名の先頭に”色換-“がついた新しいラスターファイルが作られる.
|
|
|
国土地理院2万5千分の1地図画像CD-ROMの画像(左)と色変換後の画像(右) |
2.4.14 CADのDXFファイルを「みんなでGIS」のベクトルファイルに変換
無料で利用できるJWCADなどで利用できるAutoCADのDXFファイルを読み込む.なお座標のないものにはダミーで(0,0)の座標を与えている.解釈していないものはallcomments$変数に(グループコード@値)として保存してある.
1. [DXFファイルの読み込み]を立ち上げる.
2. 読み込むDXFファイル名を指定する.書き出すベクトルファイル名を空欄にすると[DXFファイル名.csv]となる.
3. 不要な部分は適宜Excelなどで削除する.
属性値の計算とファイル統合
<ファイルの統合と変数の演算>
2.5.1 ラスタ変数の演算と統合
1. データの演算や,別々のファイルの統合はExcelで行うと柔軟性が高いが,大きなラスタ・ファイルではExcelの限界(256列×65536行)を簡単に越えてしまうし,面倒でもある.そのためラスタファイルの取り回しのためのプログラムを用意した.
2. 「みんなでGIS」を立ち上げて,メニューから[属性値の計算とファイル統合]→[ラスタ変数の演算と統合]を選ぶ
3. 変数を削除する場合は,いちばん左の「変数1」の部分だけを使う.ファイルを選択し,[読込]をクリック,さらに削除する変数を選択して[削除]をクリックする.削除候補のリストに入るので[削除実行]にて本島に削除する.[削除実行]を行うまでは実際には削除されない.
4. 変数間の演算は「変数1」に結果を格納する変数を指定する.新しい変数を書き込むと新変数が作成される.さらに必要に応じて「変数2」と「変数3」を指定し,演算の種類を選ぶ.[〜に定数を使用]のチェックボックスをチェックすると「変数2」と「変数3」にファイルから読み込んだ数でなく,その場で入力した定数を与えることができる.「変数4」をつかった条件式を設定すると,セルごとに演算を行うかどうかを制御できる.条件に満たないセルには全て欠損値が入る.[演算実行]によって演算が行われ,結果は即座にファイルに書き込まれる.
5.
複数の標高データや土地利用データを張り合わせて広域の標高データを作成する場合や,複数の空中写真を張り合わせるには以下の手順をとる
(a)[データ入力編集・空の図形の発生]から[ラスタデータ作成]を選び,必要な広さの空のラスタファイルを作成しておく.
(b)[データ入力編集・空の図形の発生]から[ラスタ変数の演算と統合]を選び,演算の種類として[統合]を選んで[演算実行]する.重なるデータは,標高なら平均しても良いが土地利用ではどちらかのファイルを優先させることになる.
6. たとえば標高の値によって紙に印刷する地図の色を変えるには,条件式の「変数4」に標高の変数を割り当て,標高の値の範囲ごとにred, green, blueなどの変数に値を指定する.
7. 変数の値はいったん一時的なデータとして読み込んで計算し,あとから結果を代入するので,同じ変数が「変数1」から「変数4」までに複数回あらわれてもかまわない.たとえば a = a + b,if a > 5 というのもできる.
2.5.2 ベクトルファイルの統合
1. ベクトルファイルの統合もExcelで行うのがいちばん柔軟性が高いが,大きなファイルでは作業がたいへんなのでベクトルファイルをマージするためのプログラムを用意した.
2. 「みんなでGIS」を立ち上げて,メニューから[属性値の計算とファイル統合]→[ベクトルファイルの統合]を選ぶ.まずファイル1とファイル2のふたつのファイル(あるいはどちらか一方)に読み込んだ後,適当なオプションを設定し,最後に[統合実行]を行う.
3. 基本的には,ファイル1とファイル2のふたつのファイルをマージした結果を新しいファイルに書き込む.「ファイル1とファイル2をマージしてファイル1に書き込む」こともできるし「ファイル1ひとつだけを操作した結果を書き込む」こともできる.
4. マージの方法として,変数名が重複する場合の重ね書きの指示や,図形名”name$”が重複する場合にこれをキーにしたマージができる.図形そのものの形やタイプが違っていても図形名が同じであれば同一図形と判断され,ファイル1の図形情報が優先的に使われる.
5. 図形の空間範囲や,属性変数値によって統合したものから図形レコードを削除する事ができる.
6. 「みんなでGIS」に固有の2行のヘッダと図形形状のデータを取り除いた,統計ソフトなどで用いるための外部ファイルに書き出すには[外部ファイルに保存]をチェックする.第1行に変数名が入ったコンマ区切りのテキストファイルになる.図形情報のなかで図形名だけが”name$”の変数名ではいっている.
7. 外部ファイルを読み込む場合は,”name$”か”name”の変数名がある場合はその値を図形名に使い,図形の形状はダミーのpoint図形となる.この変数名がない場合は適当にダミーの図形名が生成される.ダミーの図形情報を持ったファイルは「みんなでGIS」の統計機能を使うときに利用できる.
8. 図形形状の情報はファイル1が優先されるため,ファイル1に正しい図形情報が入ったファイルを読込み,ファイル2に外部ファイルを読み込むと,ファイル2の属性データを含んで正しい図形情報をもったファイルをつくることができる.これは解析の途中で外部の統計ソフトなどで計算し,その結果を「みんなでGIS」に持ち帰るときに役に立つ.
9. 50mDEMや10mDEMのpoint格子のファイルをマージするときは,「全て別図形として扱う」と「図形名のチェック省略」をオンにしておくとチェックがないので処理が早い.
10.
ある属性値をキーにして,ファイル1の複数の図形に,ファイル2の全属性値を1対多でマージすることができる.樹木個体の位置情報をもつファイル(ファイル1,外部ファイルでも良い)に,サブ・プロットの属性や種の属性(ファイル2,外部ファイルでも良い)を追加するような場合に使う.ファイル2の図形情報は新しいファイルには入らず属性変数のみがマージされる.キーとなる属性値で図形情報を並べ替えておく必要はないが,ファイル2に同一の属性値をもつ図形が複数あるばあいは最も始め(ファイルのはじめのほう)の図形の値のみが使われる.
操作は,いったん両方のファイルを詠み込んだ後に行う.
・新変数名のリストからマージのキーとする変数を選択して[キー変数]をクリック
・[キー変数で属性のみマージ]を選択
11.
上記10とは逆に,ファイルAの少数の図形をコピーして,ファイルBの多数の属性データとマージすることもできる.方針としてはA「少数の図形」の図形情報を属性変数に変換し,Bの多数の属性データにマージしたあと,図形情報を回復する.
i ExcelなどでファイルAの図形情報を属性データ化する.
・最初の2行(vector と コメント行)を削除
・図形情報の初めのtype$, name$, NodeNumをitype$, iname$, iNodeNumなど
に改名
・polygonなどで行長がちがう場合は最後にダミーの変数(たとえばEOL)をつくり
ダミーの任意文字(たとえば$など)を入れて四角いデータにし,[ベクトル
ファイルの統合]にてダミーの図形情報を付加する
ii ファイルBに図形情報がなければ[ベクトルファイルの統合]にてダミーの
図形情報を付加する
iii [ベクトルファイルの統合]にてファイルBをファイル1に,ファイルAを
ファイル2とし,キー変数を指定してマージする.
iv Excelなどで,できたファイルからダミーの図形情報やEOL変数などを
削除し,type$, name$, NodeNumを回復する
|
統合されたベクトルファイル |
|
図形情報を持つベクトルファイル |
|
先頭に変数名を持つ普通のcsvファイル |
|
統合vectorsample.csv |
← |
vectorsample.csv |
統合 |
auxfile.csv |
|
属性変数: 変数1, 変数A,変数B,red, green,blue 図形情報: vectorsample.csvの 図形情報 |
|
属性変数: 変数1
図形情報: 完全な図形情報 |
|
属性変数: 変数A, 変数B,red,green, blue 図形情報: 図形名(name$)のみ |
図2.8 図形名(name$)をキーにした外部ファイルのマージの例.標準添付のサンプルファイルなのでExcelで内容を確かめることができる.緑の背景はベクトルファイルで青い背景は外部ファイル.
2.5.3 ベクトルファイルの変数の演算
1. ベクトルファイルの変数間の演算はExcelで行うのがいちばん柔軟性が高い.またいったん外部ファイルに出力してからデータベースソフトや統計ソフトの計算機能を使うこともできるが,大きなファイルでちょっとした演算をする場合を考えてプログラムを用意した.
2. メニューから[属性値の計算とファイル統合]→[ベクトル属性変数の演算]を選ぶ.まずファイルを読み込んだ後,演算方法と変数を選択し,[演算実行]する.
3. 結果を格納する変数として新しい変数名を記入すれば新しい変数が追加される.
4. 図形ごとに演算を行うかどうかを条件で設定できる.既存の変数に結果を代入する場合は,条件を満たさない場合は既存のデータがそのまま残る.「欠損値は真」をチェックしてかつ,あり得ない条件を設定した場合(s>3 and s<1 など)は,sが欠損値の場合だけに演算が行われるはずである.
5. 計算結果は即座に同じファイルに書き戻される.「処理結果をすぐ読み込む」がチェックしてあれば処理結果が読み込まれる.計算を続ける場合は必ずこれをチェックしておく.
6. 「変数の情報を表示」をチェックすると数値変数の場合にデータ数と平均,標準偏差が変数名の下に表示される.それ以外の場合は始めの3つのデータの値が表示される.
7. 「vやwに定数を使用」をチェックすると,変数名のところに適当な定数(たとえば100.0などの数値)を置くことができる.画像出力の色変数(red, green, blue)をケースによって指定する場合などには便利かも知れない.
2.5.4 ベクトルファイルのリストを表に変換
1. ベクトルファイルのリスト形式のデータを読込み,表の形にする.特に指定しなければ上書きされずに新しいファイルが作成される.
<リストの例>
地点$,種名$,個体数
東京1, ミヤマクワガタ, 2 ←この図形の空間情報が継承される
東京1, カブトムシ, 1
東京1, コクワガタ, 3
神奈川3, カブトムシ, 4 ←この図形の空間情報が継承される
神奈川3, コクワガタ, 4
<表の例>
地点$ ,ミヤマクワガタ ,カブトムシ ,コクワガタ
東京1 ,2 ,1 ,3
神奈川3 ,null ,4 ,4
2. 文字列変数名には必ず後に$を付けておく.$が付かない場合は数値変数とみなして大小順に並べ替えようとするので,文字列(欠損を表すnull以外)が入っているとエラーになる.
3. 表の要素(中身)は全て文字列としてあつかわれる.同じ行・列の組み合わせの情報がある場合は,ファイルの後方のものが破棄される.
4. 図形情報は,行(新図形)の変数値のうち,ファイルの先頭にあったものの図形データが使われ,重複して出現した場合には以後の図形情報は破棄される.図形情報が保存された図形は属性情報も継承される.
2.5.5 ベクトルファイルの表をリストに変換
1. ベクトルファイルのリスト形式のデータを読込み,表の形にする.特に指定しなければ上書きされずに新しいファイルが作成される.
<表の例>
地点$ ,ミヤマクワガタ ,カブトムシ ,コクワガタ
東京1 ,2 ,1 ,3
神奈川3 ,null ,4 ,4
<リストの例>
地点$, 種名$, 個体数
東京1, ミヤマクワガタ, 2 ←東京1の図形情報がコピーされる
東京1, カブトムシ, 1 ←東京1の図形情報がコピーされる
東京1, コクワガタ, 3 ←東京1の図形情報がコピーされる
神奈川3, カブトムシ, 4
神奈川3, コクワガタ, 4
2. 新し区必要になる変数名(上記の例の「種名$」と「個体数」に相当)は必ず指定する.
3. 表の要素(中身)は全て文字列としてあつかわれる.新しいファイルに欠損値を含めないのがデフォルトだが,含めることもできる.
4. 図形情報は,それまでの行のものがコピーされる.表の部分以外の属性情報も図形情報と共にコピーされて継承される.
<属性値の空間的な集計>
2.5.6 図形が最近接する他の図形やセルの属性値を取得
1. 植生の調査地点から最も近い気象観測点のデータを使う,という場合などに相当する.受取側と属性データ源のファイルがともにpoint図形だけのときには,Voronoi分割と同じ結果になる.
2. [属性値の計算とファイル統合]→[最近接の観測地点の属性を収集]を選択
3. 属性データを含むファイル(ベクトル図形とラスタ画像のどちらでも良い)と,受け取る図形ファイルを指定し,[ファイル読込]する.
4. 収集する変数をリストの中から選択する.
5. 最近接データが複数ある場合の処理を指定する.受取側のpolygonの内部に複数の観測地点がある場合は距離がゼロになり,重複データとなる.
6. 変数名が重複してしまうときは,[ベクトル属性変数の演算]から変数名を変更するか,エディタやExcelなどでファイルを開いて変数名を書き換える.
7. 数値データに対して四分位や中央値,頻度集計などを求めると,カテゴリー数が非常に多くなるため,ソートなどに処理時間がかかったり,頻度集計では計算結果を格納する属性変数の数が膨大になったりすることがある.これを避けるためには,あらかじめ数値を必要な有効数字にそろえておくことが望ましい.[属性値の計算とファイル統合]からint関数をつかう.たとえばInt(x*100)/100を求めると小数点以下2桁にそろえることができる.
2.5.7 一定距離内の図形やセルの属性値を集計して,図形に付与
1. 植生の調査地点の周辺の土地利用データを収集する,という場合などに相当する.
2. [属性値の計算とファイル統合]→[一定距離内の図形やpixel属性を収集して図形に]を選択
3. 属性データを含むファイル(ベクトル図形とラスタ画像のどちらでも良い)と,受け取る図形ファイルを指定し,[ファイル読込]する.
4. 収集する変数をリストの中から選択する.
5. 収集する範囲を距離で指定する.距離ゼロのときはpolygonやareaでは図形の境界線を含む図形内部だけとなり,point,line,treeなどでは線上に重なるものだけになる.セルは中心の点として扱われる.
6. 集計方法を指定する.
7. 属性変数の値によってグループ分けして統計量を計算できる.この場合は,受け側の図形がグループごとにコピーして結果を格納する.
8. 変数名が重複してしまうときは,[ベクトル属性変数の演算]から変数名を変更するか,エディタやExcelなどでファイルを開いて変数名を書き換える.
9. 正確なpoint地点でのラスタデータのセルの値を収集したいときや,収集する属性データの源の図形名やセル番号を知りたい場合には,[かたちの情報の変換と計算]→[point地点のラスタ情報収集]を使う.この場合はセルは中心点ではなく長方形の領域として扱われる.
10. 数値データに対して四分位や中央値,頻度集計などを求めると,カテゴリー数が非常に多くなるため,ソートなどに処理時間がかかったり,頻度集計では計算結果を格納する属性変数の数が膨大になったりすることがある.これを避けるためには,あらかじめ数値を必要な有効数字にそろえておくことが望ましい.[属性値の計算とファイル統合]からint関数をつかう.たとえばInt(x*100)/100を求めると小数点以下2桁にそろえることができる.
|
|
|
|
収集先のベクトル図形の属性値として,一定距離内のベクトル図形(3個)の属性変数の集計結果を格納 |
収集先のベクトル図形の属性値として,一定距離内にセルの中心があるラスタデータのセルの(11個)の属性変数の集計結果を格納 |
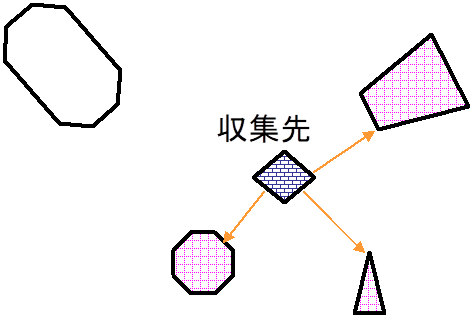
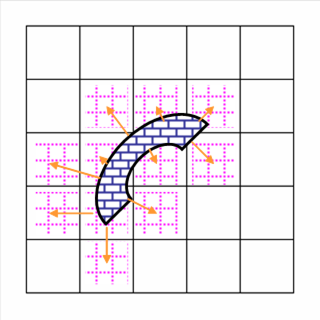
図2.9 属性を図形に収集
2.5.8 一定距離内の図形やセルの属性値を集計して,セルに付与
1. [属性値の計算とファイル統合]→[一定距離内の図形やpixel属性を収集してラスタに]を選択
2. 属性データを含むファイル(ベクトル図形とラスタのどちらでも良い)と,受け取るラスタファイルを指定し,[ファイル読込]する.
3. 収集する変数をリストの中から選択する.
4. 収集する範囲を距離で指定する.距離ゼロのときはpolygonやareaでは図形の境界線を含む図形内部だけとなり,point,line,treeなどでは線上に重なるものだけになる.
5. 集計方法を指定する.
6. 変数名が重複してしまうときは,[ラスタ変数の統合と演算]から変数名を変更するか,エディタやExcelなどでファイルを開いて変数名を書き換える.
7. 数値データに対して四分位や中央値,頻度集計などを求めると,カテゴリー数が非常に多くなるため,ソートなどに処理時間がかかったり,頻度集計では計算結果を格納する属性変数の数が膨大になったりすることがある.これを避けるためには,あらかじめ数値を必要な有効数字にそろえておくことが望ましい.[属性値の計算とファイル統合]からint関数をつかう.たとえばInt(x*100)/100を求めると小数点以下2桁にそろえることができる.
|
|
|
|
ラスタファイルのセルから一定距離内のセル(13個)の属性値の集計 |
ラスタファイルのセルから一定距離内のベクトル図形(ここでは3個)の属性値を集計. |
図2.10 当該セルの中心から一定距離内のセルや図形の属性値を集計する.
かたちの情報の変換と計算
<図形と座標の操作>
2.6.1 等値線作成と領域の多角形としての取得
1. ラスタ・データをもとに,等値線をline図形として取得する.また属性値がある範囲にある領域を多角形図形(area)として取得することもできる.
2. [かたちの情報の変換と計算]→[等値線作成と領域取得]を選択
3. データのラスタファイルと,結果の図形を保存するベクトルファイルを指定する.このベクトルファイルが既存の時は上書きされる.
4. 対象とする変数を選ぶと,最小値・平均値・最大値が表示される.
5. 処理としてはセルの間に境界線を引いてゆくが,より滑らかにするために,セルの辺の中点を結んで角を斜めに落とす設定にしてある.等値線や境界線の長さを知るにはこの設定がよいが,領域の面積が重要なときは[そのまま]を指定する.
6. 等値線のタイプは,セルひとつ分の微細な線分をひとつの図形として保存するか,1本の等値線を連続した1本の折線として保存するのか指定できる.単に図上に等値線を表示するだけなら前者のほうが画像出力での処理速度が早い.
7. 等値線は値をコンマで区切って指定する.「〜から〜まで〜間隔」と指定して値の列を自動生成しても良い.対数間隔で等値線を引くには「0.01から1000まで10倍」などと指定して自動生成する.
標準では指定値未満のセルと,指定値以上のセルの間に等値線が引かれ,指定値は上の領域に入るが,uかlの文字(小文字のユーかエル)を数値の後につけることによって,境界の値の取り扱いを指定することができる.指定例は以下の通り.
3.5u 3.5以上のセルと,3.5未満のセルの間に等値線を引く(標準)
3.5l 3.5を超えるセルと,3.5以下のセルの間に等値線を引く
8. 領域もコンマで区切って複数の値の範囲を指定できる.領域の値の範囲の指定はコロンで区切って下限値と上限値を並べる.以下のような指定方法がある.
3 値が3のセルをまとめた領域
3+ 値が3以上のセルをまとめた領域
3- 値が3未満のセルをまとめた領域
3l+ 値が3を超えるセルをまとめた領域
3u- 値が3以下のセルをまとめた領域
1:3 値が1以上3未満の領域をまとめた領域
1u:3 値が1を超え3未満の領域をまとめた領域
9. [画像ファイルに出力]から等値線の引かれた画像を作る.「色」というダミーの属性変数が作ってあって値に1が入っている.これをつかって色を指定できる.もっと細かく線の色を指定するには,[属性値の計算とファイル統合]→[ベクトル属性変数の演算]でred, green, blueの属性変数をつくって,これに適当な値を入れる.
10. 50mメッシュのDEMデータから,背景画像とするための等高線図を作るには,以下のようにすると複雑すぎない単純なイメージが得られる.
a. 国土地理院のDEMのCD-ROMから「みんなでGIS」のpointデータに読み込む.[データ入力編集]→[数値地図50mメッシュ(標高)読込]
b. 5mメッシュ程度(目的によって解像度を選ぶ)のラスタファイルを発生.[データ入力編集]→[ラスタデータ作成]
c. pointから補間してラスタへ.[形の情報の変換と計算]→[point属性を補間してラスタに](「実測値から離れても可」がオフだと早い)
d. ここで,半径25m程度の移動平均をかける.[属性値の計算とファイル統合]→[一定距離内の属性を集計してラスタへ]
e.等値線のベクトルファイルを作成する
11. 現時点でpolygon取得においてエラーが発生している.lineを取得して図形タイプを手作業でlineからpolygoinに変更するとpolygonが得られる.
|
|
|
|
|
|
16×16セル |
64×64セル |
1024×1024セル |
|
|
図2.11 補間の細かさと等値線.図2.17の16地点のデータを異なった解像度で補間してから等値線を引いた.背景の濃淡は値の大きさ. |
|
||



|
|
|
図2.12 空中写真を使った地被の自動分類の結果(4区分,図3.1上)をもとに,森林のパッチを多角形(area)として取得した.塗りつぶさずに辺だけを表示している.このようにベクトル図形にしておくとパッチ間の距離や林縁からの距離,林縁の長さなどを求めることができる. |
2.6.2 ベクトル図形のタイプの変更
1. pointやline,polygonなどの図形のタイプを相互に変換する.領域の境界線だけがほしい場合や,領域の内外反転などに使用する.[かたちの情報の変換と計算]→[ベクトル図形のタイプ変更]を選択.
2.
AreaとPolygonの内外の反転
ふつうのpolygon(多角形の内側領域)は,多角形の外側を領域とするareaに変換され,単一のpolygonで構成されるareaも内外が反転する.都市郊外の森林のパッチをpolygonとしていた場合,反転するとその森林以外の宅地や畑の領域を表す図形となる.林縁から林の中に入るに従って環境が変わるが,林内の点から林縁(宅地など)との距離を求めるには,森林polygonを反転させてからpointとareaの距離を計算する.
複数のpolygonを含むareaの反転では,(領域1 AND 領域2)の反転 = 領域1の反転 OR 領域2の反転,となるため,単純な内外の反転ではなく,単一polygonに分解してから反転する(一つのファイル内の横並びの図形は普通はORの関係).
3.
Areaを複数のpolygonに分解
複数の多角形領域で構成されるareaを,複数のpolygonに分解する.外縁(out)と内縁(in)の情報も保存するが,この情報を継承するために,結果はpolygonタイプでなく1つの多角形からなるareaとして表現される.属性変数はもとのものがコピーして継承される.
4.
Treeを複数のlineに分解
枝分かれしたTreeを複数の折線のlineに分解する.接続情報は属性変数に格納される,接続先の図形名はLineName$変数に,接続するノードの位置(その図形の始めからの順番)はLineNode変数にそれぞれ保存されるので,後からtreeを再構築できる.それ以外の属性変数はもとのものがコピーして継承される.河川を支流や上流,下流などの部分に分解して属性(水質,底質,etc.)を解析し,後から全体をまとめることができる.
5.
AreaとPolygonを輪郭線のlineに
AreaとPolygonを輪郭線だけをlineに変換する.森林polygonの林縁だけの情報がほしいときや,印刷時にpolygonの縁を協調する目的で使えるかも知れない.
6.
LineやTreeをセグメントの線分のlineに変換
折線のlineやtreeを多数の直線lineに分解する.もとの接続順はPointOrder変数に格納される.大きなlineやpolygonの輪郭の画像出力は遅いがこの機能で分解しておくと早い.属性変数はもとのものがコピーして継承される.
7.
LineやTreeを等間隔のpoint列に変換
折線のlineを多数のpointの列にする.もとの接続順はPointOrder変数に格納される.lineの属性をラスタに継承する場合の前処理にも使える.属性変数はもとのものがコピーして継承される.
8.
LineやTreeを等長のlineに変換
折線のlineを等しい長さの多数のlineに分割する.余り部分は削除される.もとの接続順はPointOrder変数に格納される.属性変数はもとのものがコピーして継承される.
9.
複数のpolygonをまとめてひとつのAreaに統合
外縁(out)と内縁(in)の情報も保存される.ひとつのareaを構成する全領域の交わり(論理積,AND)となるので,場合によっては該当領域が全く存在しないareaになってしまうこともある.属性変数は,データの最初にあらわれた被統合図形のものがつかわれて,それ以外のものは破棄される.
10.
複数のlineをまとめてひとつのtreeに統合
折線のlineをまとめてtreeにする.接続情報は属性変数からよみこむ.接続先の図形名はLineName$変数の,接続するノードの接続先図形内での位置(図形始めからの順番)はLineNode変数の値が使われる.接続先図形がない場合はtreeのいちばん始めのノードに接続され,やLineNode変数のみ欠損値の場合は接続先の図形の始めのノードに接続される.LineName$変数がrootの場合はtreeのrootになる.属性変数は,データの最初にあらわれた被統合図形のものがつかわれて,それ以外のものは破棄される.
11.
Lineを閉じてpolygonに変換
折線のlineの両端を結んだpolygon(これが外縁となる内部の領域)をつくる.途中での辺の交叉は作成時にはチェックされず,再読込時にチェックが行われる.ただし「読込時ベクトルのチェック省略」が指定されいるとチェックされない.
12.
Point列を結んでlineに変換
pointを結ぶ順番は,属性変数のPointOrder変数の値が小さい順になる.マイナスの値や小数でも良いが1×10297より大きくてはいけない.この変数が欠損値の場合は,他の結合が終わった後に,データにあらわれた順に結合される.複数のlineを一括してつくるにはLineName$という属性変数にlineの名前を書いておくと,同じ名前ごとにpointをまとめてlineをつくる.
2.6.3 座標軸の平行移動と回転
1. いったん作成してしまったデータの座標軸の平行移動や回転,長さの単位の変更をおこなう.ベクトルファイルとラスタファイルの両方とも行える.
2. [かたち情報の変換と計算]→[座標軸の平行移動と回転]を選ぶ.
3. 平行移動と,指定した点を中心にした回転,距離の単位の変更(キロメートルからメートルに変更など)ができる.
4. ファイル名と操作内容を選択し,必要なパラメータを与えて[実行]する.
5. 結果は読み込んだファイルに書き戻す.慎重に作業を行うためにはもとのファイルのコピーをとって置いた方がよいかも知れない.特にラスタファイルの回転では,逆回転しても必ずしももとのデータを回復できるとは限らない.
6. ラスタファイルの回転は,もとの空間解像度をなるべく生かしながら再サンプリングを行う.元のファイルで一つのセルのx方向とy方向のサイズが違う場合は,小さな方(解像度が高い方)を採用し,新しいファイルは必ず正方形のセルになる.新しいファイルでは,元のファイルの4角形の領域が回転したもの全体を含む広い長方形の領域を確保するため,新しいファイルはサイズが増大する.元のファイルの領域外であった部分には欠損値が入る.
2.6.4 個々の図形の平行移動と回転
1. ベクトルファイルの属性変数に平行移動量や回転角度を記載しておき,ひとつのベクトルファイルの図形を一括して移動や回転させる.属性変数の値によって,個々の図形ごとに違う動きをする.
2. この機能を使って図形の位置や方角をランダムに移動することで,たとえば動物のホームレンジの重なりの統計的検定ができる.回転しながら移動する物体の表示なども可能.また樹木の調査においてGPSで緯度・経度を調べた地点からの距離と方位を調べたマッピングデータを平面直角座標やUTM座標などの地図上の座標に一括変換できる.樹木の位置を記録したコドラートの原点の緯度・経度をGPSで測定しておき,個々の樹木の平面直角座標を計算することができる.
3. 移動量や回転角度は,あらかじめ属性変数として保存しておく.
4. かたち情報の変換と計算]→[個々の図形の平行移動と回転]を選ぶ.平行移動と,指定した点を中心にした回転ができる.
5. ファイル名を指定して読み込み,操作(平行移動か回転)を指定し,移動量や回転角などを指定した後[変換実行]する.
6. 読み込むファイル名と書き出すファイル名を同一にしておくと,作業が終わった後に自動的に読み込んで,一連の変換を次々行うことができる.
7. 変数を指定しないと,その移動量や回転角はゼロとみなす.また,平行移動してから回転するのと,回転してから平行移動するのでは違った結果になる.
|
|
|
|
|
標準添付のVectorSample.csv |
一点に集合 |
ランダムに回転しランダムな位置に移動 |


図2.13 標準添付のVectorSample.csvの図形の移動と回転
2.6.5 図形を属性値で指定した数だけコピー
1. 多数の調査地点で生物の初期個体数と生残個体数を調べることがある.このようなとき1行を1調査地点として入力されたファイルを,1行が1個体に対応するように図形を多数回コピーする.また新しい属性変数に生残個体と消失個体で別の値を付加できる.このときの変数名は「付加変数」.
2. 1調査地点を1行としたベクトルファイルを作る.繰り返し数(コピー数)を含む属性変数を用意しておく.コピー図形のうち何個に値1を割り振るのか(残りは値2)を別の属性変数に用意しておいても良い.
3. [その他応用プログラム]→[同一図形のコピー作成]を選択
4. 入力ベクトル図形ファイルと書き込みファイル名(同一でも良い)を指定して[読み込み].属性変数がリストに示される.
5. 変数のリストからコピー数(たとえば初期個体数)を指定する属性変数を選択.値の割付を指定する場合はチェックを入れて,値が割り付けられる回数(たとえば生残個体数)とその値(たとえば生残個体=1,死亡個体=0)を指定する.
6. [実行]するとコピーを含むファイルが形成される.コピー数がゼロであれば図形は削除される.新しいファイルには全ての属性変数が保存されている.
<幾何特性の計算>
2.6.6 図形の幾何的な特性を計算
1. 植生パッチの形状特性を求める場合などに使用する
2. [かたち情報の変換と計算]→[ベクトル図形の特性値]を選択
3. ファイル名を指定する
4. 必要な特性値を指定する
5. 計算結果は読み込んだファイル自身に追加される
|
|
図2.14 図形の幾何特性.黒い多角形の森林の最大内接円(紫色の円,林縁の影響),最小外接円(オレンジ色の円,ハビタットを通って移動可能な距離),最長方向と直交する幅(緑の長方形),などを求めることができる. |
2.6.7 図形間の距離
1. 生物の生育地(ハビタット)間の移動を解析するときなどに使う
2. [かたち情報の変換と計算]→[図形の相互の間の距離]を選択
3. 距離を保存する側のファイル名と,距離計算の相手側のファイル名を指定する.
4. 同じファイル名を指定するとそのファイル内の全図形間の距離が計算される.polygonとその内部に位置するpointでは距離ゼロとなる.
5. 保存方法を指定する.図形間の距離行列のような形で保存するか,最近接・最遠隔から順に保存する.後者の場合は,最近接の距離,最近接の図形名,2番目の距離,2番目の図形名,というような並びの属性値が保存される.
6. 調査地域の外周をlineで入れておき,最近接から順に並べるオプション付きで距離を計算すると,実際の解析に使える距離データがわかる.(調査地域の端の生育地では,調査地外にもっと近接した生育地が存在する可能性がある)
7. 「飛び石距離」は生物がたくさんのパッチを乗り換えながら移動するときに移動を制限する可能性があるような,乗り越えなければならない最大のギャップの大きさである.距離を保存するファイルと計算対象のファイルに違う図形群が含まれていても,両方のファイルを合わせた図形群を使って飛び石距離を計算する.
|
|
図2.15 図形間の距離. polygon,area(穴の空いたpolygon),line,tree、pointなどの相互の間の距離行列を求める。 |
2.6.8 不均一な環境での図形間の到達時間距離
1. 整備された地面は速く歩けるが,藪が茂れば遅くなり,大きな川があれば渡れないこともある.このような環境を「移動可能な速度の空間分布」としてとらえ,ベクトル図形間の距離を最短の到達時間として表現する.通過不可能な地域がある場合は,その周囲を回り込んだ距離となり,遅い場所の中に,速い場所が細長く連なればコリドーになる.直接的には時間を求めることになるが,距離の指標としてつかえる.このような距離は生物の分布拡大を解析する基礎データとしても使うことができる.
2. [かたち情報の変換と計算]→[不均一な環境での図形間の到達時間距離]を選択
3. 距離を保存する側のベクトルファイル名と,距離計算の相手側のベクトルファイル名を指定する.同じファイルを両方に指定しても良い.
4. 移動可能な早さの空間内の分布はラスタファイルで与える.移動不可能な部分は値をゼロとする.
5. 計算結果として,到達時間(時間距離)は図形×図形の行列のかたちでベクトルファイルに保存される.また別の外部ファイルとして「出発図形名,到着図形名,時間距離」のリストとして保存することもできる.それぞれの図形からの時間距離を,環境データとして指定したラスタファイルに追記することもできる.いずれも到達できない場合は,時間距離=−1になっている.
|
|
図2.16 東京港からの距離.海上の移動速度は任意に設定できるが,この図ではどこでも等しいと仮定している.能登半島など明るい部分では距離がより離れている.岸沿いにしか移動できない生物の場合は,海岸線付近を早く移動可能な場所としてラスター・ファイルに落とし,外洋や陸上の移動可能速度をゼロにする.船舶の移動の場合は湾内の航行速度などを適宜設定する.
|
<ベクトルとラスタの高速な変換>
2.6.9 point地点のラスタ情報を収集
1. 画像処理で画像のラスタデータを格子状のpointの属性に読み込むときなどに使う.実際にはラスタだけでなくベクトルファイル内のpolygonの属性も取り込むことができる.
2. 情報源のセルの位置やpolygonの図形名を取得できる.
3. ただし周辺のデータを集計することはできない.
4. [かたち情報の変換と計算]→[point地点のラスタ情報収集]を選択
2.6.10 point地点のデータを補間してラスタに
1. 画像処理で処理結果のpointデータを画像のラスタデータに変換するときなどに使う.不規則点の補間ができるので,任意の地点での気温などの観測値から地域全体の気温分布図を作成できる.同様に等高線が印刷された地図や測量結果から,標高のメッシュデータ(DEM, digital elevation model)を求めることができる
2. [かたち情報の変換と計算]→[point属性を補間してラスタへ]を選択
3. 属性を受け取る側のラスタファイルは,[データ入力編集・空の図形の発生]から,あらかじめ空のものを用意しておく.
4. 属性を受け取る側のラスタファイル名と,属性値を持っているpointを含むベクトルファイル名を指定してから[ファイル読込].
5. 双方のファイルに含まれる属性変数がリストされる.抽出する属性変数を選ぶ
6. セルに対応するpointが存在しない場合の処理方法を指定する.欠損値のままか,最近接のデータで埋めるか,補間を行って滑らかに変化する値で埋めるかを選択する.
7. 欠損値のままか,最近接のデータで埋めるばあいは,重複データの処理も指定できる.普通の数値であれば平均しても良いが,カテゴリとしての数字の場合は[後のデータで置換]を選ぶ
8.
補間のアルゴリズムは以下の通り
(a) 「斜面の傾斜の変化」が最も少なくなるような曲面を求める.
(b) 「斜面の傾斜」は隣接するセルの値の差が大きいほど傾斜がきつくなる.「斜面の傾斜の変化」は「自分の区間での傾斜」と「隣の区間での傾斜」の差が大きなほど大きくなり,痩尾根のような凸地形ではプラスに,V字谷のような凹地形ではマイナスになる.(自分の前隣のセルの高度−自分のセルの高度)−(自分のセルの高度−自分の後隣のセルの高度)として「傾斜の変化」を求めることができる.「斜面の傾斜」は標高をxやyで微分した1次微分に相当し,「斜面の傾斜の変化」は2次微分に相当する.x軸方向とy軸方向の「傾斜の変化」を単純に足算したものはラプラシアンと呼ばれる.
(c) 単純な2次微分で「斜面の傾斜の変化」の大きさを表そうとしても,プラスとマイナスの両方の値をとってしまう.そこでこのプログラムでは
「斜面の傾斜の変化」=(x軸方向の斜面の傾斜の変化)2+(x軸方向の斜面の傾斜の変化)2
としてみた.ラプラシアンの2乗ではx軸方向の凸がy軸方向の凹で補償されてしまうが(馬の鞍のような地形),この方法では補償されずにとにかく平坦な曲面になりたがる.なお,2乗でなくて「絶対値の和」や「絶対値のn乗の和」なども可能だが,数学的には2乗がいちばん取り扱いやすい.
(d) 求めるラスタファイルの全てのセルで上記の「斜面の傾斜の変化」を計算し,その合計値を最小にするようにセルの値をきめる.これで滑らかな補間になっている.
(e) あるひとつのセルの値だけを変化させ,他のセル値を全て固定したとき,「斜面の傾斜の変化」の全セル合計は,当該セル値からみると2次関数になっていて,それが最小になるセル値は以下の通り
最適セル値=(4×前後左右の隣接セル値の合計−前後左右の1つ飛んだ先のセル値の合計)/12
(f) そのセルを「最適値」にしても他のセルの値も動いてしまうので一度に最適値を決めることはできない.pointデータが存在するセルの値は固定し,実測データが存在しないセルだけ動かして,繰り返し計算を行って最適値を求めてゆく.
(g) 空間解像度を4×4,8×8,16×16と細かくしながら計算してゆき,荒い解像度での値を次の細かな解像度での,実測値が存在しないセルの初期値に使う.
(h) 一度に「最適値」まで動かしてしまうと,行き過ぎが起きて毎回の計算ごとに大きな値と小さな値を交互にとるような振動が発生してしまうこともある.振動を押さえるために[ダンパー]という値を使っている.0から1までの値を指定し,1のときは「最適値」まで一気に動かす.値が大きいと計算は速いが,収束しない可能性も高くなる.
(i) 計算の終了は,一回の計算でのセル値の変化幅が小さくなったときにうち切る.もとのpointの値の標準偏差を物差しにして相対値で「移動量比」を計算している.この相対値として[打切]を指定する.値が小さいと精度は良くなるが計算時間がかかる.
(j) 画面左下に表示される[移動量比]と[2次微分]がともに小さくなって行くが,逆に大きくなり始めると振動が発生しはじめていて収束できない.[ダンパー]の値をゼロに近づけたり,[打切]の値を大きくしたりして再計算する.あるいは,ラスタファイルの解像度を下げる.
(k) ひとつの観測点が飛び抜けた値を持っていると,ゴム風船をピンセットで引っ張ったようなピークができてしまうことがある.この値を必ずしも通らずにより滑らかにするには,いったん結果が得られた後でストレスが小さなセルは値を固定し,ごく少数のストレスの大きなセルのみを再び補間する.このためには[補間では実測値を離れても可]をチェックする.「外れ値」は上記の(c)の「斜面の傾斜の変化」の平方根について,たくさんのセルの標準偏差の何倍のところ以上のストレスのセルを補間するのかを指定する.標準の1.6では約10%程度のセルを再計算する.
(f) 50mメッシュ標高データ(およそ45mから55m間隔のpoint)から正確に50mメッシュのラスタデータ(DEM)を作成するときに,階段の幅(ラスタ)と歩幅(point間隔)が合わない現象によって滑らかでない結果になる場合は,必要な解像度よりも高い解像度(2倍くらい)で補間したあと,50mメッシュ内で平均をとったりセルの中心地点の高さを読みとるなどの対策をとることもできる.
|
|
|
|
|
図2.17 実測データのpointの位置が不規則な場合の処理. 左:実測データがない部分は欠損値(灰色)のまま.中:最近隣のデータで埋める.右:滑らかな曲面で補間 |
||



2.6.11 ラスタをタイルpolygonに (R→V)
1. ラスターファイルを4角形タイルpolygonのベクトルファイルとする.
2. ひとつの変数の 空間集計であれば属性値の集計を利用する.ここでは種別に分布を調べた多変数のラスターのマップから,ピクセル×種名のテーブルを作る.
|
|
|
|
|
もとのラスター |
テーブル化 |
リスト化 |



<属性値から図形を作成>
2.6.12 属性値を座標とするpointを作成
1. ベクトルファイルの属性値を座標値とするpoint図形をつくり,新しいベクトルファイルに収納する.
2. 新しいpoint図形はもとの図形の全ての属性値と図形名を継承する.
3. 座標に欠損値があった場合は,その図形に対応するpointは作られない.
4. 操作は [かたち情報の変換と計算]→[point作成]を選択
2.6.13 属性値を中心座標や半径とする円形のpolygonを作成
1. ベクトルファイルの属性値を中心座標や半径とする円形のpolygon図形をつくり,新しいベクトルファイルに収納する.
2. 新しいpolygonはもとの図形の全ての属性値と図形名を継承する.
3. 円をpolygon(多角形)で近似する精度として,多角形の辺の長さや辺に対応する中心角の大きさを指定する.辺の長さが短く,中心角が小さいほどきれいな円形になるが,データが大きくなりすぎてしまう.印刷時のpixelサイズ程度の長さであれば十分だとおもう.
4. 円の半径に比べて多角形の辺が長すぎる場合や,半径がゼロやマイナスの場合はpolygonではなくpointが作られる.
5. 中心座標(x, y)や半径のどれかに欠損値があった場合は,新しい図形が作られない.
6. 操作は [かたち情報の変換と計算]→[円形polygon作成]を選択
|
|
図2.18 横浜市の都市近郊の森林パッチ(黒線)の重心(黄色点)と最大内接円(緑線),最小外接円(青線).重心や内・外接円は「図形の幾何的な特性を計算」にて計算したもの.
|
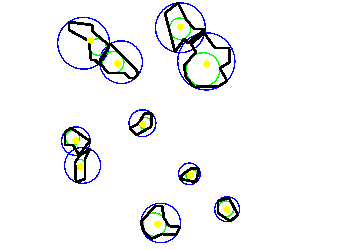
その他・応用プログラム
<統計>
2.7.1 属性値によるサンプル(図形)の自動分類 (座標づけ分割法)
1. 分割型のクラスター分析であり,ベクトル・ファイルの属性値を使ってサンプルの自動分類を行う.特にGISのソフトというわけではなく,普通の多変量解析のひとつなので,ダミーの座標データを入れておけばGIS以外の普通のデータの解析にも使える.
2. 画像から収集した地点のpoint格子(地点×波長特性などのデータ)を使えば,空中写真や衛星画像による地被の自動分類ができる.また図形の周囲長や面積などの特性値(図形×特性値のデータ)を使えば,特性の似た図形同士をグループ分けできる.生物の調査結果(地域や地点×生物の種のデータ)を使えば生態系や生物群集をグループ分けできる.
3. 植物生態学でよく使われるTWINSPAN(two-way indicator species analysis)というプログラムの手続きに似ている.おおまかにはTWINSPANで反復平均法(correspondence analysis)を使っている部分を主成分分析に置きかえ,またTWINSPANでは2分岐のみであるのに対して多くの枝を同時に出すことができるようになっている.
4.
使用手順は以下の通り
(a) [その他・応用プログラム]→[サンプルの自動分類]
(b) データの図形ファイルを指定して[読込].結果も同じファイルに新しい属性値として格納される.図形データのない普通のデータなら,第1行に変数名をおいたコンマ区切りのデータファイルを用意し,これを[属性値の計算とファイル統合]→[ベクトルファイルの統合]で,ダミーの図形情報を持ったベクトルファイルにしておく.
(c) 解析に使う変数を指定する.なお[分割階数]は分割レベルを指定する.また[最大同時分割]は一度に分割する枝数の最大を指定し,2の場合は2分木になる.ただし必ずしも指定した数だけきっちり分岐するわけではない.計算時間を短縮するためには,同時分割数を減らして分割階数を多くする.グループ分けの基準として尤度,尤度比,MDL (minimum description length),AIC (Akaike’s information criterion)を選択できる.「個別分布ごとの重み付け」では,尤度計算でデータ数の多い区分の重みを大きくし(たとえ話として富士山と愛鷹山では富士山の区間の重みを大きくする),無加重では全ての区間が平等,逆加重では逆になる.結果としては無加重が安定しているようだ.
(d) [実行]すると,右側のボックスに途中経過が表示される.この途中経過は[計算ログを保存]をクリックすると,MinnaGIS.exeがあるディレクトリのdivision.txtに保存される.
(e) 分割結果は元のファイルにDivision1, Division2, Division3, ...という変数で保存される.Division1は1回目の分割でのグループ番号である,それぞれのグループごとに次の2回目の分割が行われて,その枝のグループ番号がDivision2である.
(f) [色変数作成]をチェックすると,すぐに図示できるようにグループごとに分けた色がred, green, blueの3変数に保存される.始めからこの変数名が使われていた場合は,元からあった変数の名前が自動的に変更される.
(g) [等標準偏差を仮定]をチェックすると各区間(個別の分布,グループ)のサンプルの標準偏差が等しいと仮定する.この場合は対数尤度の計算は分散分析を使ったグループ分けの場合と同じことになる(グループ内分散を最小化してグループ間分散を最大化する区分方法).画像処理でよく使われる大津の2値化法やk-means法もこれと同じである.等標準偏差を仮定すると1サンプルだけを別の区分とすることができる.デフォルトでは区間ごとに標準偏差が違うと仮定しているので,区間ごとに個別の標準偏差を求める必要があり,分割結果のグループに入る最小のサンプル数は2である.
5.
アルゴリズムは以下のとおり
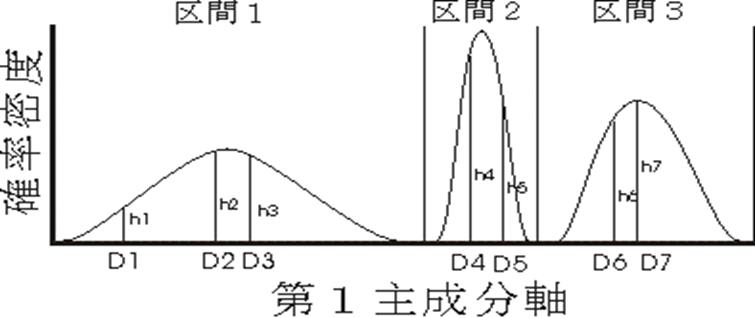
(a) 主成分分析で第1主成分軸上のサンプルの座標を求める
(b) 第1主成分軸を適当な区間に区切り,各区間のデータ点の分布が正規分布であると仮定して尤度を求める(下図のh1×荷重1
× h2×荷重1
× h3×荷重1
× h4×荷重2
× h5×荷重2
× ... に相当).基本的には尤度が最大の分割方法を選択したいのだが,下図の区間が小さくなると確率密度関数のピークの値が非常に大きくなるため,たとえもとのサンプルの分布が一様分布であっても分割区間数を増やすだけで尤度が上昇してしまう.これを避けるためにいくつかのオプションを用意した.
尤度: 求めた対数尤度そのものを最大化する
尤度比: 区間ごとの一様分布を最尤推定してバックグラウンドとし,正規分布モ
デルでの対数尤度から,その区間分割数での一様分布のなかで最大であっ
た対数尤度を差し引いたものを考え,これを最大化する
MDL: MDL= −最大対数尤度+log(サンプル数)×パラメータ数/2 を最小化する
AIC: AIC= −2×最大対数尤度+2×パラメータ数 を最小化する
MDLとAICでは同じ尤度なら区間数が少ない(パラメータ数の少ない)分割方法が選択されるはずだが,実際には尤度上昇の効果についてゆけず役に立たない.無駄な分割の多さでは, 尤度>MDLとAIC>尤度比 となっていて,尤度比を使うと無駄な分割が止まることが多い反面,グループ間の重なりが大きかったり全体の分布の尖度が大きかったりすると分割してほしいところを分割してくれないこともある.
(c) 区分されたデータごとに上記の(a)と(b)を繰り返す.
(d) 「尤度」などで分割して実際のグループ数と最大同時分割数が一致していない場合は,分割された結果をもう一度統合しなおす作業も有効であろう.
|
|
|
図 自動分類の方法.D1, D2, etc., は各サンプルの座標.ここでは3つの区間に分けることを想定している. |
|
|
|
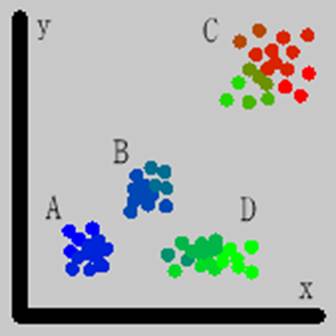
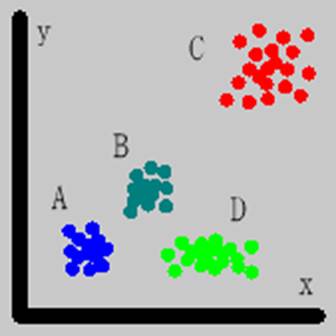
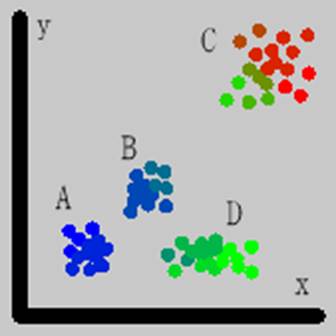
図 x軸とy軸の座標値を変数として自動分類した結果.最大2分割で4階の分割を行った. 尤度比を使ったものでは無駄な分割は行われずに,A,B,C,Dの4グループがきれいに分かれている. その他の方法はみな同じ結果であり,A,B,C,Dの4グループは上位の分割で分かれているが,さらに下位の分割も行われている.「尤度比」では最大4分割3段階など細かく分割する設定で計算しても同じ結果になる.いずれも加重無し. 左上:尤度 右上:尤度比 左下:MDL 右下:AIC
|
|
|
|
2.7.2 ロジスティック回帰
生物の生息地を予測する統計モデルとしてよく利用される.目的変数を生物などの在・不在(1:在,0:不在)にして,説明変数を環境要因(気温,降水量など,数値のみ)とする.モデルは以下のとおり.
出現確率 = E/(1+E)
E = exp(定数項 + a1×変数1 + a2×変数2 + ...)
乱数を使った再サンプリングで統計的な検定やモデルの検証を行う.パラメータの最尤推定での最適化には小柳のダビッドソン・フレッチャー・パウエル法サブルーチンを使っている(「Fortran77による数値計算ソフトウェア」,1989年,丸善).
1. [その他・応用プログラム]→[ロジスティック回帰]を選択
2. 入力ファイルを指定して読み込む. 変数を先頭行に置いたふつうのCSVファイルの場合は,いったん「みんなでGIS」のベクトルファイルにしてから入力する.[属性計算とファイル統合]→[ベクトル・ファイルの統合]から,ファイル1に外部ファイルを指定し,ひとつのファイルだけを[統合]して新しいファイルにすれば,ダミーの図形情報が付加されたベクトルファイルができる.
3. 目的変数(従属変数)と説明変数(独立変数)を選ぶ.目的変数は0か1のどちらかの値を取る数値.従属変数は複数同時に評価できるが,数値のみである.
4. 統計的な検定やモデルの検証を行うためには,bootstrapかモデル検証のオプションを指定する.元のデータから指定回数だけデータをランダムに再サンプリングして計算を繰り返す.例えば,たくさんの地区の中でたくさんの調査地点で在・不在を調べているばあいに,地点ごとに再サンプリングするには[図形(1行)を単位として再サンプリング]を選ぶが,地区ごとにまとめて再サンプリングするには[変数ごとにまとめて再サンプリング]を選んで地区名が入れた変数を指定する(文字列変数は必ず変数名に$を付ける).
5. 実行すると,繰り返し計算の全結果が表として出力される.[保存]でいったんファイルに書き出してExcelなどで見ると読みやすい.データ数が異なる再サンプリングの結果を比較しやすくするため,対数尤度をサンプル数で割ったものを「尤度/資料数」として示している.検証オプションを指定すると,モデル構築に使われなかった残りのデータで「検証尤度/資料数」を計算する.この表中でパラメータ値が空白の場合はその変数は使われていない.全ての変数が空白で「尤度/資料数」が-1.0E+300になっているところは,最適化に失敗して(繰返数が上限に達した)パラメータが得られなかったところである.尤度はマイナスの値をとるが,値が大きいほど(絶対値が小さいほど)モデルのあてはまりがよい.
6. ExcelのソルバーやRなどでも可能.
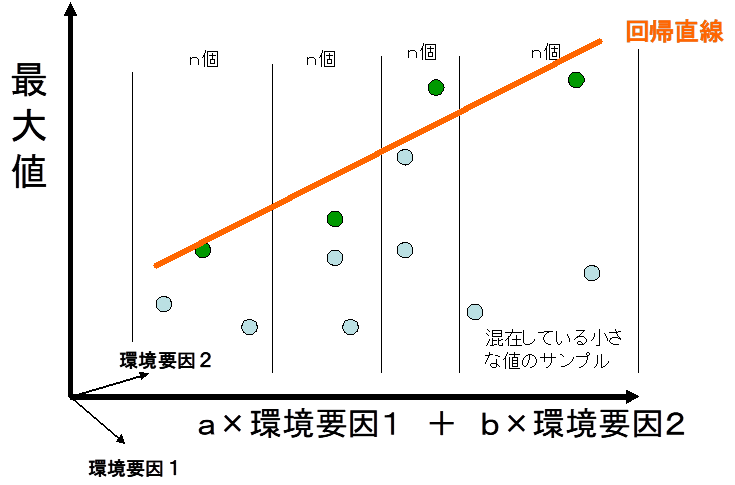
2.7.3 最大値回帰
1. 特にGISとは関係ないが普通の統計ソフトでは不可能なので自作した.樹木の最大樹高は環境で制限されるが,樹高の高い林の中にも小さな若木がたくさんいるため,平均的な樹高の値を使っていては環境との関係を解析できない.このような場合のために最大値回帰のプログラムを作成した.
2.
計算のアルゴリズムは以下の通り
a.データをn個ずつ等数にグループ分けする(最大値はサンプル数に依存するため,区間幅でなく個数で切る)
b.各グループの最大のサンプルをえらび,これ使って直線回帰をおこなう
c.上記のaとbをブートストラップ法で再サンプリングしながら繰り返す
d.ブートストラップの試行での相関係数の二乗(r2)がもっとも大きくなるような環境要因を求める
e.いちどに考慮する環境要因を増やし,もっとも良いブレンド比で環境軸を構成する.(ステップワイズ法的)
3. おおむね普通の線形の重回帰でのステップワイズ変数選択と同じだが,区間の最大値を使う点が異なる.また環境軸を構成する環境要因のブレンド比が違えばデータの順位が変わってくるため,試行錯誤でパラメータを求めている.
4. ステップワイズ変数選択と同じように,間接的な影響による見かけの相関の高い変数はモデルから除外される.普通のステップワイズ法では一定のルールを使って新しく導入する変数や削除する変数を決めているので変数増加法と変数減少法で結果が異なる場合があるが,ここでは総当たりで最適の組み合わせを求めている.
5. 1つのグループのデータ数が1の場合は普通の線形重回帰と同じことになる.経験的にはグループ数が5個程度がよいようだ.確率的な再サンプリングを行うので,データ数がグループ数で割り切れなくてもよい.
6. 最大値だけでなく最小値でも同様の計算ができる
7. [その他・応用プログラム]→[最大値回帰]を選択して起動する
8. データが入っているベクトルファイルを選択して[読み込み].図形情報のない外部ファイルの場合は[属性値の計算とファイル統合]→[ベクトルファイルの統合]からダミーの図形情報をつけたベクトルファイルを作ることができる.
9. 計算結果は任意のテキストファイルに保存できる.
|
|
|
図.最大値回帰 |
2.7.4 個体数の期待度数との差の検定 (カイ2乗検定)
1. 普通の統計の検定そのものだが,たまたま自分が利用していた統計パッケージにはプログラムがふくまれていなかったので自作した.
2. たとえば,都市近郊の森林パッチをpolygonとして入力して面積を求め,それとタヌキの観察回数との関係を調べる場合などに使える.5つの林の面積が10.5m2, 120.9m2, 2000m2, 3000m2, 6000m2だったとして,タヌキの発見回数がそれぞれ0, 2, 1, 3, 6回だったとする.森林面積を横軸に,観察回数を縦軸にとってグラフをつくって見ても良いが,観察回数が少ないので発見数が偶然の影響で変わってしまいそうで不安である.もしチョウのなかまのヒカゲチョウが0, 200, 100, 300, 600個体いたのなら偶然の影響はもっと少ないだろう.カイ2乗検定ではこの偶然の影響の大きさを調べる.
3. [その他・応用プログラム]→[出現個体数の統計検定]を選択.
4. データを含んだベクトルファイルを選択.図形データのない普通のデータなら,第1行に変数名をおいたコンマ区切りのデータファイルを用意し,これを[属性値の計算とファイル統合]→[ベクトルファイルの統合]で,ダミーの図形情報を持ったベクトルファイルにしておく.
5. [実際の出現数]の変数と[期待度数]の変数を選択して[実行].実際の出現数は整数のみの数値変数である.ゼロでも良い.期待度数は小数点以下の値があっても良い.ただしゼロやマイナスの場合は計算から除外される.
6. 「森林によってタヌキの発見数に違いがあるか」という検定では,期待度数は全ての林で等しくする(期待度数の変数名を空欄にしておいても良い).計算結果は右のリストボックスに示される.χ(カイと読む)2乗値をみて,実測の値が95%点の値より大きければ95%水準で有意に森林による違いがある(P<0.05と表記).もし森林ごとに等しい確率でタヌキが発見されるなら,100回同じ調査をやってもこんな偏りのある観察結果が出るのは5回以下しかないことがわかる(すなわち「林ごとに同じ確率で見つかる」という仮説には無理がある).99%点の値より大きければ99%水準で有意(P<0.01).
7. 「タヌキの発見数は単に林の面積が大きいことによるのか」という検定では,「期待度数」に林の面積を入れる.もし実測χ2乗値が95%点を超えれば,林の大きさ以外の別の要因が働いていることになる.それ以下であれば林の大きさでも説明できてしまう.6番の検定で有意であって7番では有意でなければ,とりあえず林の大きさが重要な要因と考えられる.
8. 常緑樹林と落葉樹林など林のタイプの影響を調べる場合は,林のタイプを1行とするようにExcelなどでデータを集計する.同じようにn行×m列のクロス集計表の検定では,表の各要素を1行とするようなデータをつくる(図形データは計算には使わないのでx=0, y=0のpointなど架空のものでよい).行を生かした期待度数と,列を生かした期待度数など,必要な期待度数をExcelなどで適宜準備する.
9. プログラムの内部では,期待度数の割合に応じて乱数で観察数を発生させ,χ2乗値(期待度数と観察度数の差を期待度数で相対値化したものの2乗和)を計算する試行を[試行数]だけくりかえし,結果の頻度分布を調べる.このようなやり方をモンテカルロ法と呼ぶ.
10. 古典的な生物統計の教科書に載っているような漸近p値を使っていないため,観察度数がゼロの場合も検定できる.また正確確率による検定よりも大きなデータを扱うことができる.
11. 計算結果はChiSquare.txtファイルに保存することができる.
12. 同じような状況では尤度比検定(G検定)も多く使われる.χ二乗検定では期待度数と観察度数の値があれば,さまざまな現象であっても計算できるのにくらべて,尤度比検定では実際におきている現象のモデルを明示的に与える必要があるので汎用性の高いプログラムを作りにくい.このためここではχ二乗検定を採用した.
2.7.5 図形の再ランダムサンプリング
統計的な検定やモデルの検証のために,乱数を使って図形を再サンプリングする.
1. [その他・応用プログラム]→[ランダムサンプリング]を選択
2.
入力ファイルと出力ファイルを指定して読み込む.
変数を先頭行に置いたふつうのCSVファイルの場合は,いったん「みんなでGIS」のベクトルファイルにしてから入力する.[属性計算とファイル統合]→[ベクトル・ファイルの統合]から,ファイル1に外部ファイルを指定し,ひとつのファイルだけを統合して新しいファイルにすれば,ダミーの図形情報が付加されたベクトルファイルができる.
図形の属性変数としてサンプルされたか,されなかったか(bootstrapの場合はサンプルされた回数)の情報が保存されるが,サンプリングの繰り返しごとに別のファイルにすることもできて,この場合は直接外部ファイル(先頭行に変数名を持ったCSV)も出力できる.
3.
再サンプリング方法を指定する
bootstrap法では,母集団(もとの図形のあつまり)のサンプル数(図形数)と同じ数のサンプルをランダムに選ぶ.同じサンプルが重複して選ばれることも多い.
「一定の確率でサンプリング」では,図形(サンプル)ごとに乱数を使って再サンプリングするかどうかを決めてゆく.選ばれる図形の個数は二項分布になるので,サンプルが全く選ばれない(個数ゼロ)こともあり得る.
「モデルの検証」では,指定した比率でモデル構築用のサンプルと,検証用のサンプルを選ぶ.選ばれる図形の個数は一定だがサンプルの組み合わせは異なる.
4. 個々の図形(1行のデータ)を単位として再サンプリングするだけでなく,指定した変数の値によってサンプルをグループ分けし,グループ単位でランダムサンプリングすることもできる.
2.7.6 個体の自動配属
生物のハビタットのパッチ(定員の上限と下限が決まっている)を訪れる多数の個体を,ハビタットに配属させる.瞬間の個体分布のなかで最も出現確率が高いケースを得る.
1. 各ハビタットを図形とし,個体を変数とする.個体がハビタットに存在する確率(全ハビタットの合計1.0)をベクトルファイルとして与える.同じファイルにハビタットの定員(上限と下限の個体数)を指定する.
2. 個体どうしの優先関係をウェイトとして特殊な別のベクトルファイルで与える.変数は個体で,図形(サンプル)はひとつのみである.
3. 出現パターンによる主成分分析で近隣のハビタットを探索し,記録データのない個体を所属させることも可能(point spread関数).
4. 組み合わせ最適化のほか,各ハビタットで最も存在確率が高い個体から順次所属させることもできる.

図 個体1から個体5を生息地1から4に所属させる.
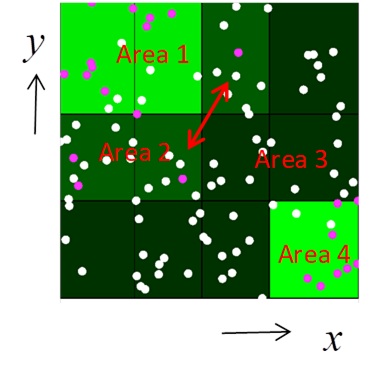
2.7.7 空間領域の統合型クラスター回帰
地域の様々な地点で生物の在不在を調べたようなデータに使用する.地域を規則的に縦横のグリッドに分割し(絶対距離でなく調査地点数が均等になるように),隣接していてかつ出現確率が近いグリッド同士を連結して領域を作ってゆく.値が近くても空間的に接していないもの同士は結合しない.このとき最もAICが小さくなる領域パターンを探索するが,初めの分割数を指定すると最適の領域パターンは自動的に求まる.ただし最初の分割数(空間解像度)の最適値を探すことはできないので,結果を議論するときには空間解像度を明示しして議論する.領域を凸包に限定したり複雑さを定義して制限することも可能だが,自然のパターンは凸包とは限らないこともあり空間スケールを明示的に意識するのが良いだろう.
1. データはベクトルファイルである.従属変数(目的変数)は1か0の値を取るひとつの変数か,同一地点での調査回数と,在であった回数の2変数の1組を指定する.この値が似ている地域をまとめてひとつの領域とする.
2. 独立変数(説明変数)は標準では地理座標だが,好みの数値変数を多数同時に解析できる.
3. 変数の分割数の上限と,分割メッシュ(グリッド)あたりのデータサンプル数の下限を指定する.グリッド数=分割数^投入変数の数,なので多変数でしかも分割数が多いとデータ不足が起きる.メッシュ当たりのデータ数(平均)の下限を越えると計算を行わずに警告メッセージが記録されるので,これに関係する解析結果は利用しない.分割数は指定した値だけでなく,それより小さな分割数の範囲も探索する.
4. 計算結果は,領域数ごとの所属領域番号がデータファイルの属性変数に追加される.このほかログとしても示されるので保存しておく.
5. 全変数の組み合わせ以外に,指定した従属変数の全ての組み合わせでの最も良いAICの結果が出力される.分割数が多い(すなわちメッシュあたりのデータ数が少ない)場合はAICが良く(小さく)なる傾向がある.1変数の場合はどれがよいか,2変数の場合はどの組み合わせがよいか,などの観点で変数の組み合わせを選ぶと良い.
6. 計算ログにはメッシュごとの集計データが出力される.従属変数値の範囲(上限,下限)や所属する領域番号,出現確率などである.従属変数が地理座標の場合はメッシュ情報がClusterPolygon.csvという名前のGISファイルに出力されるので,そのまま地図に重ねて表示できる.
7. 領域(類似した出現確率をもち隣接する範囲)間の隣接性を示す行列と,出現確率がピークとなる領域の情報もログに含まれている.隣接しているが統合されていない領域どうしの出現確率は統計的に異なっている(下図Area1とArea2,AICによるモデル選択).ただし隣接していない場合は有意には異なっていないかもしれない(下図Area1とArea4).
|
|
図 テストデータを解析した例.4×3メッシュに分割された領域の最適な統合パターンを示す(4×4分割を指定したがこちらの方が良かった).紫の点は発見された調査地点,白の点は発見されなかった地点である.Arera 1〜4までの4つの領域が得られた.緑色が明るいほど領域の出現率が高い. |
2.7.8 外来生物の侵入順序解析−過去の歴史による予測
外来生物には類似した分布拡大パターンを持つ種があり,南西から拡大する種や太平洋ベルト地帯の都市から地方へと拡がるものも多い.このプログラムでは,分布拡大パターンを比較して種をグループ分けするための類似度を求める.さらに類似したパターンの種を合成して一般的な分布拡大パターンを求め,これをもとに分布拡大中の種の未来の分布を予測する.多数の地域間を1対1で比較して侵入時期の早さを比べた星取表を作って解析する.
Koike, F. and Morimoto, N.
2018. Supervised forecasting of the range expansion of novel non-indigenous
organisms: alien pest organisms and the 2009 H1N1 flu pandemic. Global Ecology
and Biogeography 27:991–1000. https://doi.org/10.1111/geb.12754
1. データは,地域の図形に対して,種の初確認時期(年月日など)を数値で与える.まだ分布していない場合は「未分布」,現在は分布しているが侵入時期不明の場合は「分布」,現在生息しているかわからない場合は「不明」とする.
2. 解析対象の種を選択する.また予測対象種も解析対象種に含めておく.類似パターンの種に大きなweightを与え加重平均する(予測対象種そのものは加重平均に含まない).
3. 分布拡大時期の予測値は相対値で与えられるが,すでに分布済みの地域が多いときには実際の年月日にスケーリングする.分布初期でも,次に侵入するであろう地域(ひろがってゆくパターン)が予測できる.
<メタ個体群シミュレーション>
2.7.9 個体群の拡大過程(メタ個体群のシミュレーション)
生物の生育可能なハビタットがパッチ状に分布しているとき,パッチ間の分散(種子散布など)によって生物の分布が広がってゆくようすを調べるシミュレーションモデルである.
1. 地理的なパッチの分布は「みんなでGIS」のベクトルファイルとして表現する.ハビタットは点状,線状,多角形領域,など何でも良い.ハビタットはその生物が存在するか(値が1),いないか(値がゼロ)のどちらかの状態をとる.パッチごとに計算するので,段丘斜面の林のようにとても細長いハビタットや大きな面積のハビタットは一定のサイズに収まるように小口切りにして別のpolygonとして入力しておくとよいかもしれない.
2. シミュレーションの時間の単位は任意に設定できる.植物の場合は種子散布から繁殖開始までの期間をとると良いかもしれない.
3.
距離と移住確率の関係を表す移住関数にはロジスティック関数と積タイプの移住関数を使うことができる.ロジスティック関数は普通の統計ソフトでパラメータ推定ができて便利だが,複数の分布拡大経路(自然拡大+人為的分散)で分布拡大しているような場合には後者が良い.いずれも親のいるハビタットから距離が離れるに従って,空きハビタットに子が定着する確率が減少する.とくに遠いところでは定着確率が指数関数的に減少する.下図に示すように各種の「距離」を同時に扱うことができる.また外航船の入港トン数のように外来生物の媒体の量を,地域の固定値として与えることができる.またロジスティックモデルではこの固定値を環境要因のために使う事ができるが,複数の環境要因を考慮している場合はハビタットのパッチごとに事前に計算してひとつの要因にまとめておいても良い(このときパラメータc=1).
分布が飽和したときの出現確率に相当する適合度として,積モデルでもパッチごとの環境の良さを指定できる.パッチの特性からロジスティック関数などで与えられている場合はあらかじめExcelで計算しておく(たとえばFukasawa et al. 2009, Ecol Res 24: 965-975).
4. ハビタットからの絶滅確率は,(a)絶滅なし(パッチからの絶滅確率が無視できそうなとき),(b)移住関数で自分のパッチ(距離ゼロの)への定着に失敗する確率を絶滅確率とする,(c)別途固定値を指定,(d)パッチごとの絶滅確率を属性変数として指定,の3つのオプションを選ぶことができる.指定する絶滅確率は計算ステップあたりである. パッチの面積に依存した絶滅確率を与える場合は,あらかじめパッチごとの絶滅確率を計算して属性変数にいれておく.
5.
使用する準備として,まず地域のハビタットをベクトルファイルに入力する.[データの入力編集]→[ベクトル図形のマウス入力]など.このとき初期状態の変数を1つつくり,既に生物が分布しているハビタットには1を,空のものにはゼロを入れておく.また直線距離以外は距離行列を求めておく.またロジスティック回帰などで移住巻数のパラメータを求めておく.
パラメータの推定では「前時点で生育していた最近接の生息地からの距離」や「前時点で生育していた生息地から流入する媒体量の合計」などを知る必要がある.このプログラムで[パラメータ用ファイル作成]をチェックしておくと,1ステップ後のこのような量を外部ファイルに保存できる(シミュレーションをしないモード).目的変数となる1ステップ後の在・不在情報はExcelなどで別途書き込む.
6. [その他・応用プログラム]から[個体群拡大のシミュレーション]を選択
7. ハビタットのベクトルファイルと,距離行列ファイルや媒体輸送量行列ファイル(行と列の先頭に図形名が入ったコンマ区切りのテキストのCSVフォーマット.行や列は並べ替えられていても良い),を指定して[読込].直線距離のみをつかうなら距離行列ファイルや媒体輸送量行列ファイルは省略可.
8. 初期分布を与える変数名,移住のロジスティック関数のパラメータを入力,計算につかわない要因はパラメータ=0にしておく.計算するステップ数,ファイルに記録するステップ間隔,繰り返し回数(乱数を使うので計算するたびに結果が異なる),などを指定して[実行]する.ロジスティック関数のパラメータの求め方はKomuro & Koike2005などの論文を参照.またロジスティック式を 1/(1+exp(ax+b)) とおいてパラメータを求めた場合は,aとbのパラメータのプラス・マイナスの符号を逆にする必要がある.
9. パラメータ設定値や生物が生息するハビタット数の計算経過は右のリストに表示される.この内容をファイル(デフォルトでDispSim.log.csv)に保存することもできる.ハビタットごとの生物の在・不在の経過(デフォルトでは全試行での平均出現確率)は,入力したのと同じベクトルファイルに属性変数として追加されている.変数名は「ステップ?_繰返し??」で,世代ごと繰返しごとに,不在はゼロ,生物が分布する状態は1として記録される.
10. ブートストラップ法などでパラメータのセットが多数得られている場合は,試行ごとにランダムに選択して試行をくり返すことができる.コンマ区切りテキスト(csv)のパラメータ・ファイルのフォーマットは以下の通り.下記の表の1行がセットで選択されるので,パラメータ間に相関がある場合も利用できる.
|
parameter |
|||
|
a, |
b, |
c, |
d |
|
-3.05E-05, |
-1.65E-08, |
0.00E+00, |
0.999972 |
|
-3.71E-05, |
-1.88E-08, |
0.00E+00, |
0.999964 |
|
-3.09E-05, |
-1.42E-08, |
0.00E+00, |
0.999982 |
|
-5.16E-05, |
-3.24E-08, |
0.00E+00, |
0.999995 |
|
-4.20E-05, |
-2.43E-08, |
0.00E+00, |
0.999953 |
|
-4.27E-05, |
-2.55E-08, |
0.00E+00, |
0.999983 |
11.過去の分布の復元を行うことができる.今年において好適生息地Aに到達していないが,最隣接する好適生息地Bと少し離れた好適生息地Cに到達しているとする.前年の分布を考えると,もし前年にBに到達していたなら今年Aに来ている確率はとても高いので(この確率は分布拡大カーネルで計算できる),前年はAとBともに不在で,Cのみに到達している状態が最尤となる.このようなローカルな最尤法をくりかえすことで,過去の分布を順次さかのぼりながら復元してゆくことができる.このとき不適ハビタットにより不在であるのか,好適だが未到達であるのかも考慮される.
|
|
図 外来種シュロ(ヤシ科の庭木)の分布拡大の仮想的なシミュレーション例.明るい緑の点はシュロが生育するハビタットで,黒に近い濃い緑は空のハビタットである.青色のハビタットにのみ生育する状態から出発して100ステップ(世代)後の状態を示す.シュロの散布能力は横浜市内での実測値を使用している(Komuro & Koike 2005).シュロは一部の地域を除いてすでに広く分布しているが,このシミュレーションは都市の生態景観での分布拡大可能性を調べるためのものである. |
|
|
図 このプログラムで扱うことができる距離.直線距離以外は距離行列(あるいは媒体の輸送量の行列)として読み込む.障害物を回り込む距離は[形の情報の変換と計算]→[不均一な環境での到達時間距離]で求めることができる.
|
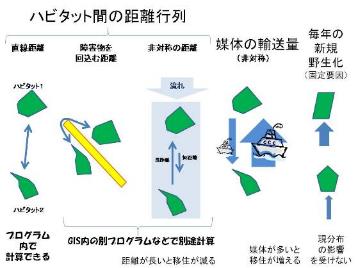
2.7.10 外来種の最適制御戦略
分布拡大しつつある外来種の最適制御戦略を以下の手順で求める.考える将来の時点(5年後か10年後か)によって最適戦略が変わってゆく.地域個体群分割パターンや最適除去パターンはベクトルファイルに保存される.
1. クラスター分析で地域個体群を検出
2. 全ての地域個体群の組み合わせで個体群を除去しシミュレーションを行う
3. 最もコストパフォーマンスの良い除去パターンを求める.
2.7.11 種子散布カーネルをもとめる
母樹を原点として,周辺への種子や幼樹の散布のしかたを表す関数を求める. カーネルは単純な指数関数で,
1本の母樹からの種子密度=exp(a×当該母樹からの距離+b)
トラップの中の種子数は近隣の複数の母樹からの種子の合計であるので,誤差関数にポアソン分布を仮定してaとbを最尤推定する(局地的な空間スケールではランダムな落下を仮定).母樹の種子生産量は全ての個体で一定と仮定している.上記の式(母樹のある原点がもりあがったパラソルのようなかたち)をふつうの2次元空間で積分すると母樹あたりの種子生産量を求めることができる.参考文献はRibbens et al. (1994); Clark et al. (1999); Ohtani & Koike 2005など.
細かなメカニズムを組み込んだモデルもあるが(母樹サイズによる種子生産の違い,複雑なカーネル関数や誤差関数,etc.),パラメータが多くなると必要とするデータ量も多くなり,また最尤推定も安定しなくなるため,散布カーネルを使って次のステップの研究を進めるにはこれくらいが最もシンプルでロバストな方法だろう.場合によっては種子の生残・発芽・定着などの過程をブラックボックスにして母樹と幼樹の関係だけで考えたほうがメリットが大きいこともある.ただし空間的にもっと詳しくするには樹冠を等面積の多数のpolygonに分割して小さな母樹の集合のように扱っても良いかもしれない.
1. 種子トラップや幼樹数を調べた調査プロットを,pointやpolygonなどのベクトルファイルにして,種子数や幼樹数を属性変数にしておく.種子数や幼樹数は面積あたりの密度には換算してはいけない.誤差分布にポアソン分布を仮定しているので数えた数をそのまま使うことがとても重要.
2. 母樹の位置を別のベクトルファイルにする(根元の位置のpointや樹冠のpolygonなど).
3. [形の情報の変換と計算]→[図形相互の間の距離]にて種子トラップと母樹の相互の距離を求める.全母樹との距離を計算しても良いが,最近接n位までの計算もできる.3〜5個体まであれば十分.現地にてトラップから最近接n位までの母樹をマッピングしてひとつの母樹ファイルに入れた場合は後者の方法.
4. [その他・応用プログラム]→[分散カーネル]にて起動
5. 種子トラップのファイルを読み込む
6. 種子数を入れた変数名と母樹からの距離を入れた変数名を指定する.母樹からの距離を入れた変数は,最近接n位までであればn個の変数だが,全母樹であれば母樹数と同じ数の変数になる.このような変数は距離計算時に自動的に作成されている.
7. 実行すると計算結果がリストボックスに現れる.尤度に*マークが付いている場合は,最適化で繰り返し数が上限を超えたものなのであまり良くない可能性もある.
8. 信頼区間を求めるならブートストラップ法を選択する.
<地形環境>
2.7.12 地形データをもとにした日射量の計算
1. メッシュ標高データ(DEM,ラスタファイルにしておく)をもとにして地面の日射量を計算する.日射計算の基礎になるような,さまざまな天候を含めた天球上の輝度の頻度分布に関する情報は意外に少ない(平面での受光量のデータや,晴天時の詳細なモデルはとても多いが,それでは役に立たない.天球を多数の領域に分け,領域ごとに輝度値の頻度分布を測定するのはとても楽な観測のはずなのだが...).ここでの計算方法は以下の通り.
2. 太陽の運行(方位と高度)を30分おきに計算する
3. 8方位の地表仰角によって地形による陰の部分を求める(直射光,散乱光とも)
4. 大気圏外の太陽定数は1.95cal/cm2/min.
5. 直達光の計算は,大気透過率(大気の吸光度で,太陽が真上から入射すると仮定したときの,地表の直達光/大気圏外の光の比)によってベア・ランベルト則で大気中の直達光が減衰する.太陽の高度が低いと透過する空気の量も増えるので減衰が大きい.
6. 晴天時の散乱光は,天球を60個の等面積の領域に分割し,水平面拡散光日射がベルラーゲ式の値になるように,各領域に等しい輝度を与える.大気透過率が小さいほど拡散光は多くなる.
7. 曇雨天時の散乱光も同様に天球を60個の等面積の領域に分割して求めるが,適当な大気透過率を与えてそのときのベルラーゲ式の拡散光日射を曇雨天時の天球上の輝度分布としている(このときの直射光は捨てている).曇雨天用の大気透過率0.4では,日本の標準的な晴天時の大気透過率0.7のときの拡散光の約3倍となる.晴天でなく曇雨天になる確率を[曇雨天の確率]で与え,この比率によって曇雨天時の日射と晴天時の日射を加重平均する.なお,曇天時に晴天時の全日射量(散乱光+直射光)よりも日射量が大きくなることは現実にあるが,大気透過率をあまり小さくしすぎると拡散光が強くなりすぎる.
8. 起動するには[その他・応用プログラム]→[日射環境].計算する期間の積算エネルギー量(MJ/m2)が得られる.特定の日の1日分の日射量や,1年を通した午前中だけの日射量なども求めることができる.時間あたりの平均値は[データ入力編集]→[ラスタ変数の演算]で計算する.
9. 水平面日射量は1m2の水平な面に入射する日射量(MJ/m2)である.地形の影響は地表仰角による陰のみである.
10. 斜面日射は,その地点の傾斜のある地面1m2に入射する日射量(MJ/m2)である.地形の影響は地表仰角による陰と,太陽の方向と斜面の向きの位置関係の両方による.太陽に向いた斜面では太陽が斜面に垂直に入射するので日射量が多くなる.
11. 投影日射は,地図上の1m2に入射する日射量(MJ/m2)である.地形の影響は地表仰角による陰と,太陽の方向と斜面の向きの位置関係に加え,さらに地表の傾斜による地表面積/投影面積比の影響を受ける.南向きの急傾斜地では北向きの谷底と比べてとても大きな値になる.
12. このほか,計算の途中に必要となる方位仰角や地表の傾斜,方位なども出力できる.
13. 解放角(スカイラインを見回して,地表仰角が一定値以下になる角度)の計算は,方位数を指定して自動で行われるようになった.
|
|
|
|
|
|
|
図 7月1日の水平面日射(左上)と斜面日射(左下),投影面日射(右上),解放角度(右下).投影面日射はコントラストがとても大きいので相対的に暗い部分が多くなっている.大気透過率や曇雨天確率などのパラメータは標準設定を使い,図3.3の標高データから計算した. |
|



2.7.13 地形データをもとにした集水量の計算
1. メッシュ標高データ(DEM)をもとにして,メッシュごとの集水量を求める.集水面積は土地の湿り方をあらわすので,生物の生活にとっては大切な環境要因である.また,ラプラシアンや傾斜のような簡単な地形パラメータも求めることができる.必要に応じて[属性値の計算とファイル統合]→[セルの属性を集計してラスタに]によって適当な空間スケールで移動平均を計算する.計算結果は標高データのファイルに追記される.
2. 求める集水量は,降水が蒸発散なしに地表を流下すると仮定したときに,各メッシュを通過する水量である.山頂のように他のセルからの流入がないところでは自分の降水量のみとなる.
3. 標高データ(DEM)はあらかじめラスタファイルにしておく.
4. [その他・応用プログラム]→[集水面積と起伏]を選択
5. 標高データが入っているラスタファイルを選択して[読み込み]
6.
集水面積や集水域の重要度を求めるときには止水域面積の割合(%)の上限を指定しておく.これは止水域情報を格納するメモリーの量を決める.大きくしすぎるとメモリー不足になる.
島嶼などで海の面積割合がおおきな場合は,DEMのpoint情報からラスターファイルに変換する時点で,point属性値の高度を欠損値nullにしておくと,陸上地形から外挿された海中地形が得られ,標高マイナスで陸から離れると深くなるため止水域がなくなり,計算可能となる.
7. 標高変数を選択し,必要な地形パラメータをチェックして[実行].集水量の計算結果の変数名はcatchmentである.1000mmの均一な降水を仮定すると,集水面積が求められる.
8. このときオプションで「集水面積」を選ぶとメッシュの上流の集水面積(m2)が得られる.メッシュサイズが大きいと集水面積も多くなる.「比集水面積」を選ぶと,等高線と平行な1mの長さの線分を通過する水量である比集水面積 (specific catchment area, m2m-1」が得られ,メッシュサイズの影響を受けない.土壌環境の湿り気を表す湿潤度(wetness index)は,[ラスタ変数の統合と演算]によって ln(比集水面積/tan(傾斜)) として求めることができる.
9. [止水域をあらわす変数を作成]をチェックした場合は,止水域に1から順に通し番号がふられ,その番号をもったメッシュデータが標高データのファイルに追記される.止水域以外にはゼロが入る.変数名はstillwaterである.
10. このファイルの範囲外からの水の流入が起こりうる場所を欠損値とするには[範囲外からの流入がある地点を欠損値に]をチェックしておく
11. 場所による降水量の違いを反映させるには,標高データと同じファイルに降水量(単位はm)をメッシュデータとして入れておく.なお,降水量ではなく有害物質の初期分布(1m2あたりの量)を入れておけば,水の移動に伴った有害物質の流下範囲を知ることができる.
12. 湿原などの地域をメッシュデータに入れておくと(湿原をゼロ以外の任意の数,湿原以外をゼロか欠損値),湿原に流入する水の何パーセントが集水域内の各メッシュを通るのかを計算できる.このためには[集水域の重要度]をチェックし,湿原などの分布を入れた変数を[重要度評価対象のセル]に指定しておく.
13. 4近傍でメッシュの傾斜を計算しているので,1メッシュ幅の堤防のような,とても細かな地形変化には対応できないことがある.
14. DEMのできの良さ(自然な地形になっているかどうか)や,地形データの入力ミスをチェックするためには集水面積を画像として表示するとよくわかる(値の桁の幅が大きいので[ラスタデータの統合と演算]で対数変換しておく).
15. 海のような止水域が大きいと計算中にメモリ不足になる可能性が高い.海や湖の面積が極力小さくなるようにDEMデータを切り取っておく.切り取るためには,[データ入力編集・空の図形の発生]→[ラスタデータ作成]にて,目的の計算範囲であって同じ空間解像度の空の新規ラスタファイルを作成しておき,[属性値の計算とファイル統合]→[ラスタデータの統合と演算]によって標高値をうつす.
16. ラスタファイルしかないDEMの空間解像度を変えるためには,いったんpoint格子のベクトルファイルにデータを移したあと(ラスタのセルサイズと同じ間隔の空のpoint格子を作成し,[かたちの情報の変換と計算]→[point地点のラスタ情報収集]にてpointにデータを移す),細かな空間解像度の空の新規ラスタファイルを作成しておき,[かたちの情報の変換と計算]→[point属性を補間してラスタに]によって補間しながら新しいDEMのラスタファイルを作る.
17. またDEMの補間のために海などの水面に微細な凹凸ができると結果が乱れる.このような場合には[属性値の計算とファイル統合]→[ラスタデータの統合と演算]によって一定値以下の標高はすべてゼロにする,などの処理をしておいても良い.
18.
「止水域の割合が大きすぎる」というエラーメッセージが出た場合は[止水域の比率]の値を大きくする(0-100%のあいだ).
「メモリーが足りない」とのエラーメッセージが出た場合は[止水域の比率]を小さくするか,計算範囲を狭めるか,セルのサイズを大きくしてセル数を少なくする.1GBのメモリーがあれば500×500セル程度は計算できると思う.
19. 集水面積,比集水面積,集水域重要度は, 2005年1月6日から2005年7月20日までの版を使った場合は不具合があるので再計算をお願いします.
|
|
図 DEMからもとめた集水面積と止水域.集水面積は対数変換してあるが,青色の濃いところで大きい(谷地形).平地や扇状地では地形的な水の流れは幅広く拡がっており,現在の水路と一致しない.右下の合流点近くの水田には止水域(湖)が出現している(水路があるので実際は排水されている).国土地理院の50mメッシュ高度を使い2万5千分の1地形図画像(鶴巻温泉周辺)に重ねた.
|
<野外調査支援>
2.7.14 ラインセンサスの座標計算
1. 野外調査で常にGPSを使えると良いのだが,実際には林冠の状態の影響も受け急峻な谷地形では使えないし,条件によっては測定に時間がかかる.狭い範囲の樹木などの個体位置をすべてGPSで測定するのは現実的ではない.実際にはルート沿いに巻き尺をひっぱって測量しながら,小型のレーザー距離計などで巻き尺と直交方向の距離を測って生物の位置を記録するような調査を行うことは多い.このようなデータをつかって生物の位置情報を地図上にマッピングするためのプログラムである.
2. センサスのラインは折れ線(line)としてベクトル図形ファイルに入れておく.複数のラインの区別は図形名変数「name$」で行う.
3. 個体の位置情報は,センサスのライン名(ベクトルファイルの図形名と同じ名前を入れる),ライン上の位置(軸方向水平距離で巻き尺の読みの値)と,その位置でのライン方向と直交方向の距離(進行方向右側が正),の最低3変数を含んだ外部ファイル(先頭行に変数名があるコンマ区切りのテキストファイル,CSV)に入れておく.これ以外に多くの変数があっても良い.
4. [その他応用プログラム]→[ラインセンサス座標計算]を選択
5. センサスのラインのベクトル図形ファイルと,個体の位置情報の外部ファイルを指定して[読み込み].外部ファイルの変数がリストに示される.
6. 外部ファイルの変数から「ライン上の距離」,「垂直方向の距離」,「ライン名が入った変数名」をそれぞれ選択して[実行].結果は個体位置の外部ファイル名にpoint.csvがついた新しいファイルに保存される.これは「みんなでGIS 」のベクトルファイルで,個体はpoint図形になっている.上記3変数以外のすべての変数も保存されている.
7. センサスのラインに高度差がある場合は,巻き尺の読みはライン上の水平距離にならない.ライン上の水平距離を求めるには,ラインに沿った垂直断面を考え(オーロラのカーテンのようなイメージ),まずこの垂直断面上でx方向を「ライン上の水平距離」,y方向を高度とし,「ラインから離れる垂直方向の距離」を全てゼロとして,このプログラムで計算して,各個体の「ライン上の水平距離」を計算しておく.Excelなどでファイルを整形した後,次に再びこのプログラムを使って,今度は水平面での座標の計算を行う.
|
|
|
図 ラインセンサスデータの座標計算 |
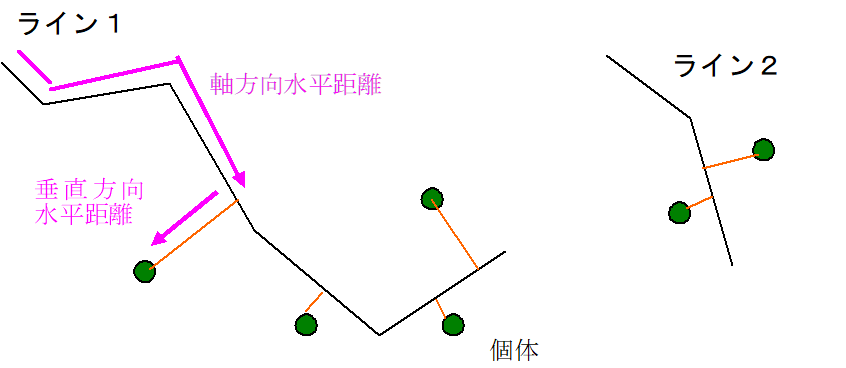
2.7.15 同一地点で重複測定したデータをリストに変換
1. 同一プロットのひとつの種の多数の個体を測定した場合などに,個体ごとの多数行のリストに展開する
2.
データの書式は以下の通り.固定変数は,緯度, 経度,
地点名$, 種名$の4変数.
<入力>(可変長の特殊ファイル)
緯度, 経度,
地点名$, 種名$,
測定値
緯度1, 経度1,
地点名1, 種A,
D1, D2, D3
緯度1, 経度1,
地点名1, 種B,
D4
緯度2, 経度2,
地点名2, 種A,
D5
<出力>(標準的な外部ファイル.このあとで一括座標計算を行うことができる)
緯度, 経度,
地点名$, 種名$,
測定値
緯度1, 経度1,
地点名1, 種A,
D1
緯度1, 経度1,
地点名1, 種A,
D2
緯度1, 経度1,
地点名1, 種A,
D3
緯度1, 経度1,
地点名1, 種B,
D4
緯度2, 経度2,
地点名2, 種A,
D5
3. [その他応用プログラム]→[重複測定からサンプルリスト作成]を選択
<地理座標を使わない特殊な解析>
2.7.16 図形間距離の尤度分布から地図再構築
サンプル(図形)の相互間の距離行列から地図を再構成する方法にはMDS(Multi Dimentional Scaling)などの方法がある.ここでは距離の数値ひとつでなく尤度の分布を与えることで,「距離は50m以上」,「距離不明の組み合わせが混在」,「方向性のある非対称の距離」などのデータに柔軟に対応し,推定した地図の信頼度の表示も可能とする. 「頻度からの尤度による傾度分析」を利用して入力データを作成できる.
|
|
図 14種の植物どうしの距離(シカによる嗜好性の差)の尤度分布をもとにした再構成.円は他種との距離の標準偏差を示し,種によって信頼性が異なる.再構成された空間内の距離スケールは本来の距離に対応するが,原点の位置は任意であるが,ここでは最も円が小さな種を原点に取っている.
|
|
|
|
図 求めた座標の信頼性を表す尤度マップ.点はサンプルの位置(上図).ひとつのサンプルだけを動かし,他を固定して描いた.色が明るい等値線で尤度が大きい. 多くのサンプルに囲まれたもの(青,アオノクマタケラン)は比較的単純な山だが,端に位置するサンプル(赤,アブラギリ)は他のサンプルのまわりに回り込む地形となる.
|
|
|
|
図 植物種間の距離(有方向)の尤度分布の例で,上記の作図のもとになるデータの一部をグラフ化したもの.左上がりの曲線は距離の上限がわからない組み合わせだが,上部は平坦のため任意の距離値で良い.欠損した組み合わせは一様分布(どの距離でも可)となる.この図の範囲外の尤度はゼロと仮定している.
|
|
2.7.17 頻度からの尤度による傾度分析
シカ被食圧に対して基準ロジスティック関数によって線形に個体の食害率が変化すると仮定し,被食個体数と非被食個体数から二項分布を利用して横軸上の尤度分布を作成する.距離の最尤推定値も得られるが,ここで出力されるSpDistanceLikelihood.csvファイルを使って「図形間距離の尤度分布から地図再構築」を行い,種の嗜好性値を得ることができる.なお[距離に方向性あり]をオフにすると対称な距離が得られる.
|
|
図 様々な地点での被食データ.ひとつのデータ(ある地点で3個体被食され,2個体は被害なし,など)に対応した横軸上の尤度を一本の曲線で示す.単純に右上がりの曲線は全ての個体が被食されていたケース.調査個体数が多いと位置は低いが鋭いピークとなる(最下の茶色の曲線).
|
2.7.18 一対比較による傾度分析
ひとつの地点でのシカによる植物の被食のレベルを,植物種間の一対一で比較して星取り表を構成し,その固有ベクトルとして植物の嗜好性値を得る.なお,同様な結果は「頻度からの尤度による傾度分析」と「図形間距離の尤度分布から地図再構築」を組み合わせても得られるが計算時間がかかる(尤度法).この方法(固有値法)は種数が多い場合も計算が速いため,多種を同時に解析するには現実的な方法である.ただし地点の調査個体数が少ない場合などには尤度を用いた方法が有利である.
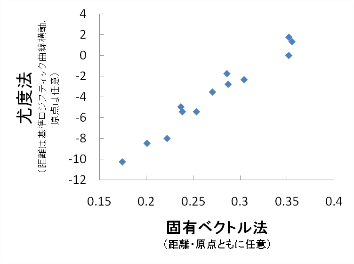
図 一対比較による傾度分析(固有ベクトル法)と,「頻度からの尤度による傾度分析」と「図形間距離の尤度分布から地図再構築」の組み合わせ(尤度法)の比較.異なる方法でシカの植物種への嗜好性を計算したが結果はきわめて類似していた.
2.7.19 尤度による出現確率の評価
総調査回数と出現回数から出現確率の尤度分布を得る.これを確率密度関数として,他のモデルで予測された期待確率のデータからのずれの大きさをサンプルごとに計算する.得られた値(デフォルトの変数名AboveExpected)が0.5であれば,外部から与えた期待確率が尤度による確率密度分布の中央値に位置する.0.5より小さければ期待確率は過大評価で,0.5より大きければ期待確率は過小評価である.また,出現確率(区間0-1)を多数に等分割して尤度分布をもとにした確率分布をあたえることもできる.
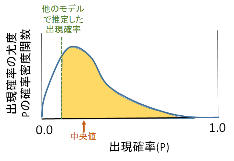
図 出現確率の尤度分布.
2.7.20 遺伝子頻度から導入個体数推定
もとの集団と導入集団のハプロタイプ出現回数(比率ではなく出現回数そのもの)をあたえて,導入個体数の尤度分布を得る. 導入個体数が多ければ導入集団の遺伝子頻度はもとの集団と近いものになるが,少なければボトルネック効果により大きく揺らぐため,これを利用して導入個体数を推定できる.
2.7.21 類似度Jaccard CC
群集間の類似度を計算する.
<地理座標を使わない特殊な解析>
2.7.22 全天写真の自動判読「空と森Sora to mori」 (2005年9月4日より,2012年9月28日更新)
全天写真の連続自動解析を行う.
フィルムに撮影してスキャナで読み込む場合は写真の位置あわせが重要だが,デジタルカメラでは画像ファイル上の同じ位置に撮影されているので位置あわせは重要でないため簡略化した.かつてMS-DOSのビデオ入力システム用に同様のソフトを作ったが,当時は相対光強度10%程度以上でなければ自動で2値化の閾値を決められなかった.しかし2000×1500画素であれば十分なデータが得られるため相対光強度1%以下の照葉樹林の林床でも閾値を自動的に決められるようになり連続自動処理が実用的になった.
天球の輝度分布はCIEのStandard overcast skyを仮定している(天頂角zの輝度 = 1+4*exp(-0.7/cos(z)),天頂の輝度を地平の約3倍と仮定したもの).この相対光強度は一般的に散乱光の強度を与えると言われているが,長期間の積算を考慮すると直達光も天球上では,地平での輝度が小さな広い光の帯となるため,南北などの方位が考慮されないことをのぞいては,それほど違わないように思える.また植物は意外に光環境に鈍感なので相対光強度10%と3%では違いが現れるが,10%と8%くらいだとふつうは差がでない.
<写真の撮影>
画角180度の魚眼レンズをつけたデジタルカメラを使う.撮影された画像は円形になる.暗い林では画素数が多いほどよい.露出は林冠に覆われない空が少し明るく林冠がシルエットになるくらいに設定し,シャッタースピードや絞りは固定してマニュアル・モードで撮影する.空が開けた場所でオート・モードにて空(太陽を含まない)の露出を調べるとよい.なおこのとき隅々まで写った写真も1枚写しておくと画像の中心位置などを調べるときに便利.オートのままでの撮影は林冠が1層の場合にはよいが,屋久島以南の照葉樹林や熱帯多雨林のように樹冠が何層も重なっている場合は,最上層の葉群が消滅してしまう.
なるべく画像処理されないプレーンな画像ファイルを得られるようにする.画像のエッジ強調をOFFにして,ファイルのタイプはjpegのような情報を失うタイプの圧縮方式はなるべく避ける.ただし高解像度で圧縮率がそれほど高くなければjpegでも問題ないようだ.
|
|
|
図 全天写真の例 |


<使い方>
1.
画像ファイルは24bitのBMPファイル(赤・緑・青の各8bit)に変換しておく.tiffやjpegなどからBMPへ多数の画像のフォーマットを一括変換するソフトは
http://www.vector.co.jp/soft/win95/art/se200307.html など数多くある.
画像フォーマットはPhotoshopなどの画像処理ソフトで読み込んで[イメージ]メニューの[モード]や[画像解像度]で確認できる.
2.
画像ファイルのリストをテキスト・ファイルにする.デフォルトはPhotoFile.csv.1行にファイル名(パスを入れてもよいと思う)と白黒の閾値決定方法(明るい白の部分が空,黒が葉群や枝幹)をコンマ区切りで記述する.閾値決定方法をAとすれば閾値は自動的に判断される.数値(1-254)を指定すると指定した閾値が使われる.ちなみにもっとも明るいところの輝度が255である. Excelの連番でファイル名を作ると楽だが,ファイル名が間違っていたり,消去して存在しないファイル名が入っているとその時点でプログラムが終了する.ただし結果のファイルをみればどこで止まったかがわかる.例は以下の通り.
DSCN2062.bmp, A
DSCN2063.bmp, 131
DSCN2064.bmp, A
DSCN2065.bmp, A
Excelで作ったファイルは「メモ帳」などのエディタにドラッグ&ドロップして内容を確認して,むだなコンマや引用符などがないか確認しておく.
3.
180度全体が明るく写った写真を使って,
・天頂(画像円の中心)の座標
・画像円の半径
を画素数で計る.画像の左下角を原点(0,0)にする.中心座標は円の上下左右の端から計算するとよい.各種の画像処理ソフトでもできるが「みんなでGIS」の[画像ファイル入力]でもできる
4. 各種のパラメータを設定して[開始]をクリック.実行中に2値化された画像が表示されるが,緑で示されているのは光環境の計算に使用した点である.[2値化画像を保存]をチェックしておくと,この画像が「ファイル名-BW.bmp」の名称で保存される.原画像とサイズが違うが,実際の計算は原画像で行われている.
5.
結果は指定したファイル(デフォルトのファイル名はPhotoLog.csv)にコンマ区切りのテキストで保存される.1行にファイル名,白黒閾値,相対光強度(%)が記述されている.自動閾値設定を指定して閾値探索に失敗した場合はその旨が記載されている.例は以下の通り.
ファイル名, 白黒閾値, 相対光強度(%)
DSCN2062.bmp, 130 , 83.9544643142715
DSCN2063.bmp, 131 , 81.8064262583614
DSCN2064.bmp, 109 , 9.59756694498584
DSCN2065.bmp, 113 , 9.88198739455157
6. 自動閾値設定では天球の状態が同じであっても,明るい林では閾値が高くなり暗い林では低くなるが,これは望ましいことである. 画像のボケは避けられないため,明るい空に葉がまばらに散っているとき,周辺の空からの光により葉の部分の輝度は細い葉で高く,幅の広い葉で低くなる.逆に暗い林冠下でごく小さな空が見えているとき,空の部分の輝度は林外で写した写真での空よりもかなり暗くなっている.このため,明るい林では閾値を高く,暗い林では低く設定する必要がある.
7. 原理的に空が全くない場所や全く空ばかりの写真からは閾値の自動判定はできない.保存されている2値化画像で確認しておく.
<主なカメラとレンズの組み合わせでのパラメーター>
|
カメラとレンズ |
設定解像度 (単位は画素数) 幅×高さ |
天頂の座標 (単位は画素数) (幅方向,縦方向) |
視野の半径 (単位は画素数) |
投影方式 |
|
ニコンクールピックス995, ニコンFC-E8 |
2048×1536 |
(1050,750) |
750 |
等距離射影 |
|
キャノンEOS Kiss χ2, シグマ8mmF3.5 EX DG CIRCULAR FISHEYE |
4272×2848 |
(2114, 1425) |
1229 |
等立体角射影 |
|
キャノンEOS Kiss χ2, シグマ8mmF3.5 EX DG CIRCULAR FISHEYE |
2256×1504 |
(1126, 755) |
634 |
等立体角射影 |
|
ソニーαNEX-C3, 安原製作所「まどか」 |
2448×1624 (画像サイズS,縦横比3:2,画質ファインjpegをbmpに変換) |
(1224,811) |
792 |
正射影 |
|
オリンパスTG-6, FCON-T02,ズームは最もワイド側 |
1280×960 (画像サイズS,縦横比4:3,画質N,jpegをbmpに変換) |
(632,451) |
430 |
等距離射影 |
天頂座標や視野の半径を求めるには,露出オーバーだがフレアがない写真を撮影し,bmpに変換後に画素座標で直接GISに読み込む.等値線作成機能でpolygonを取得したあと(エラーが出るなら折線lineを取得してからexcelなどでpolygonに文字列置換),GISの最小外接円を取得する機能を利用する.
2.7.23 天球を当面積に分割
半球を等しい面積の球面上の4角形(あるいは3角形)で分割する.方位角と仰角が出力される.
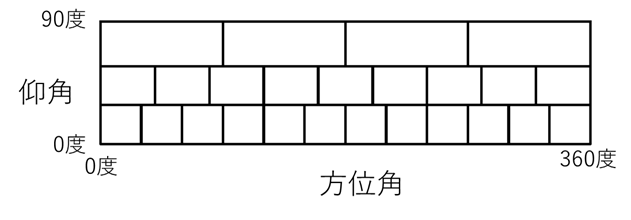
図.分割された小領域を角度で表示したもの.球面上では等面積になる.
2.7.24 天球上の輝度分布
多方向の平面日射の値から,拘束付き最小自乗法で天球上の輝度分布を逆計算する.天球の分割を記述するファイル(中心の方位角,仰角,当該多角形の面積ステラジアン)は上記の「天球を当面積に分割」でもとめることができる.
2.7.25 葉群解析用レーザースキャナ (1997年9月11日より,200年5月11日更新)
レーザー距離計を使った林冠トモグラフィを試作しました.写真を用いた方法よりも簡単にできます.
|
|
|
|

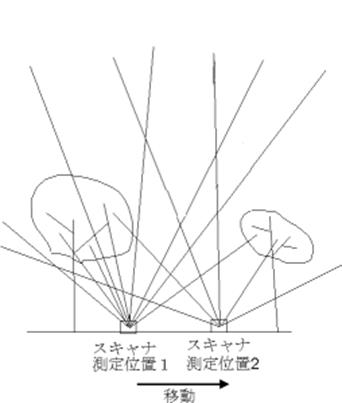
図 装着された機器(左),スキャンのイメージ(中).同一の対象を移動しながら複数の地点からスキャンできる.コントロール用の画面(右).
<システム構成>
レーザー距離計 ライカ社(地上測量・工業計測部,03-3292-9815),Power DATA DISTO RS232(4.75mw, 620-690nm, 測距機能80m,ビーム径0.5mrad,定価29万円,新機種のDISTO MEMOのほうが良い)
方位と高度の自動制御 Meade社,LX200天体望遠鏡(定価39万円)
システム全体の制御と葉群密度の計算など DOS/Vのノートパソコン(Windows95,RS-232Cポートが2つ必要)
<ソフトウェアの概要>
1.林冠トモグラフィ機能 (森林の林冠の3次元的な葉群密度分布の自動測定)
2.トータルステーション機能 (反射板不要の3次元座標測定,座標既知地点をもとにした最小二乗法での測定器据付位置・方位の計算(平行移動とxyz軸回転))
3.レーザー距離計と天体望遠鏡にキーボードから直接コマンドを送る機能
<使用例>
|
|
|
|
|
図 大山,三ノ沢の河床にあるヤマハンノキ(左側),ブナ(右手前),ヤナギ類(右奥)の樹冠.座標軸の1単位は1.25mに相当し空間解像度も1.25m×1.25m×1.25m.計測は1地点(6.0, 7.0, 1.06)から行い,ビーム数は1296本,測定にかかった時間は旧システムで約6時間.1997年8月のデータから計算した. |
横浜国立大学の環境科学研究センター前の環境保全林.2000年に測定. |
|
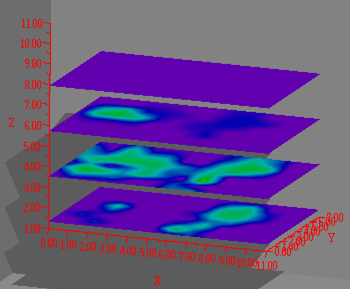

<利用法>
1. 現地での座標系を決めておく.基本的に3次元だが,幅が1グリッドで計算すれば2次元断面ができる.
2. Laser.exeを立ち上げる.
3. [Canopy tommography]を選ぶと操作パネルが現れる.
4. 座標系を設定する.水平x軸,水平y軸,高さz軸で葉群密度を測定する範囲と解像度を設定する.単位はメートル.
5. 読み込むファイル名を指定する.[FILES]の枠内の[File selection]から入力ファイルを選択.
6.
計算オプションを設定する
・オフライン計算では[FILE DATA ANALYSIS OPTION]で[File data only]をチェックする.これをチェックしないと,ファイルからのデータを読んだ後で機械の操作が始まる.
・[GROUND
CANCELL]ではレーザーの最遠データから地形の起伏を推定する機能だが,上向きや上斜めのデータのみならチェックしなくて良い
・そのほか,[COMMON
OPTION]の[Max
dist]はレーザー距離計の距離が無限大になったときに便宜的に設定する距離.初期設定のままでよい.
7. [Go]で計算が行われて,全ての結果はファイルに記録される.
<入力ファイルのフォーマット>
1.
コンマ区切りのテキストファイル.1ビーム1行にして,コンマ区切りで以下の内容を書く.
日付,時刻,機械のx座標(m),機械のy座標(m),機械のz座標(m),空データ(現在は未使用の欄),ビームの方位角h(度),仰角v(度),葉に当たるまでの距離d(m)
2. 日付や時刻は計算に使わないので何でも(空白でも)良い.
3.
座標系は以下の通り
・機械のホームポジションの方位をy軸方向とする(たとえば北)
・x軸はy軸と直交して中学校の数学と同じ向き(たとえば東)
・z軸は垂直上方向.斜面などではマイナスになることもある.
・ビーム方位角h(度)はy軸から反時計回り
・ビーム仰角v(度)は上向きがプラス
・ビーム距離d(m)は機械位置からh方位,v仰角の方向で葉に当たるまでの距離.当たらなかったら十分大きな値を入れておく.
表1.データの例.1行が1ビーム.左から日付,時刻,機械位置x,機械位置y,機械位置z,空データ,ビーム方位角h,仰角v,葉に当たるまでの距離d
|
#2000-03-30#, |
#1899-12-30 11:44:37#, |
-0.7371578, |
13.67582, |
1.453734, |
, |
-8.719750738, |
-155.5853363, |
9.829 |
|
#2000-03-30#, |
#1899-12-30 11:44:40#, |
-0.9312158, |
13.79474, |
1.449389, |
, |
-6.761241585, |
-153.367897, |
12.291 |
|
#2000-03-30#, |
#1899-12-30 11:45:44#, |
-0.7811721, |
13.57197, |
1.442147, |
, |
-3.67328451, |
-156.4657094, |
1.00E+25 |
|
#2000-03-30#, |
#1899-12-30 11:45:51#, |
-0.8688597, |
13.82428, |
1.441705, |
, |
-3.490715723, |
-153.8819666, |
17.537 |
1.00E+25は葉群の隙間を抜けて空に行ったビーム.このようなビームはとても重要.
<結果の読みかた>
計算のオプションを表示
Calculated in 000-05-08
Source file: D:\My Documents\Laser\ynu\RawData.csv
X from -8m to 8m resolution 8 subareas
Y from 0m to 16m resolution 8 subareas
Z(vertical) from -2 m to 18m resolution 10 subareas
Max value of laser data: 100m
Ground cancel: 0.5m
Sky data (1E+25) in source file was ignored in ground topography estimation.
計算結果の表
|
x方向 枠番号 |
y方向 枠番号 |
z方向 枠番号 |
x方向 下限座標値 (m) |
x方向 上限座標値 (m) |
y方向 下限座標値 (m) |
y方向 上限座標値 (m) |
z方向 下限座標値 (m) |
z方向 上限座標値 (m) |
葉群密度 (m-1) |
葉群密度の 標準偏差. 二項分布を仮定 (m-1) |
葉群密度 −標準偏差 (m-1) |
葉群密度 +標準偏差 (m-1) |
|
X |
Y |
Z |
Xmin |
Xmax |
Ymin |
Ymax |
Zmin |
Zmax |
Foliage density (FD) m^-1 |
FD assuming even distribution m^-1 |
FD -SD |
FD +SD |
|
1 |
1 |
1 |
-8 |
-6 |
0 |
2 |
-2 |
0 |
-255 |
-255 |
-255 |
-255 |
|
1 |
1 |
2 |
-8 |
-6 |
0 |
2 |
0 |
2 |
0.12078 |
0.109521 |
0 |
0.220131 |
|
1 |
1 |
3 |
-8 |
-6 |
0 |
2 |
2 |
4 |
0.29564 |
0.257284 |
0.108741 |
0.409315 |
葉群密度の-255は計算できなかったグリッド.
<変更点 2000年3月>
現地での測定を高速化(約3倍,DISTO MEMOを使用)
トータルステーション機能との連携強化(座標が既知の地点をポイントすることにより測定器の座標や座標軸の回転を計算)
地形の自動検出と地面からの反射の自動的な除外
葉群密度の計算において葉群分布の偏りの影響を補正
<その他>
2.7.26 確率計算器
調査データ数が少ない場合に,尤度分布の中央値や平均値を利用することができる.一様事前分布による事後分布の中央値などに相当する.
<小数データをもとにした出現確率の推定>
m地点調査して目的の種がn地点で発見された場合には出現確率=n/mと計算し最尤推定値にもなっている.しかし少数地点のデータしか得られなかった場合には出現確率が0や1の値を取りやすく,オッズ比などの計算が不能になる.このようなときには尤度の地形はなだらかで,左右に歪んだ分布をしていて,地形のピーク(最尤値)による出現確率と,平均値や中央値との違いが大きくなっている.少数データの場合に通常の出現確率(最尤値)に代えて平均値や中央値を用いると穏やかなオッズ比が得られる.
<小数データをもとにした出現個体数の推定>
調査によりk個体が出現したとき,個体密度λの尤度分布をもとめる.事前の知識としての真の個体数(密度)のありそうな程度には偏りがなく(一様),調査ではポアソン分布をあたえるようなサンプリング方法を採用したと仮定している.多数の調査データがある場合はコンマで区切って入れる.外来種の根絶事業で捕獲されない時期が継続したとき,密度の確率分布を考えるために利用できる.
2.7.27 中央値のブートストラップ検定
コンマ区切りで入力した2つのグループのデータの中央値をブートストラップ検定する.改行が入っていると(テキストボックスでは改行は見えないが),行ごとに比較し,初めの行からの中央値の積算値の検定も行う.
3.使用例
3.1 地図上の任意の位置の座標(平面直角座標)を調べる
1. 地図を平面直角座標を使ってラスタファイルに読み込む.
2. [データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]を選択
3. 背景画像は上記の地図のラスタファイル,入力ベクトルファイルはダミーで何か入れておく.
4. 地図画像が表示され,カーソルを動かすとカーソルの位置の座標値が表示される
3.2 ラスタデータ(画像,メッシュ値)からベクトルの格子データへの変換
5. ラスタデータのメッシュにあわせて,プローブ用のpoint格子か,長方形polygon格子を生成する.できればpoint格子のほうが以後の処理が早い
6. 長方形polygon格子の場合は,[属性値の計算とファイル統合]→[一定距離内の図形やセル属性を収集して図形に]を選択して,集計範囲の距離ゼロでデータ収集
7. point格子の場合は,[かたちの情報の変換と計算]→[point地点のラスタ情報収集]を使う.
3.3 ベクトルの格子データからラスタデータへの変換
1. 長方形polygon格子の場合は,[属性値の計算とファイル統合]→[一定距離内の図形やセル属性を収集してラスタに]を選択して,集計範囲の距離ゼロでデータ収集
2. point格子の場合は,[かたちの情報の変換と計算]→[point属性を補間してラスタに]を選択
3.4 生物の生育環境の解析と分布予測図の作成(GAP分析など)
1. 環境の地図を用意する.土地利用図などをラスタファイルに読み込んで,複数枚の地図にわたっている場合は[ラスタ変数の演算と統合]で1つのファイルにまとめておく.気象観測結果などはベクトルファイルのままでも良い.
2. 生物の分布図を用意する.調査地点(pointやpolygonなどが混在しても良い)をマウス入力や,座標の直接入力で,ベクトル図形ファイルにする.図形は点でも折線でも,多角形でもよい.生物の現存量や「在・不在」を表す属性変数をつくって調査結果をいれておく.できれば生物がいなかった場所も含めた,全部のベクトル図形がほしいが,もし生物が存在するところだけの地図しか得られなかったら(よくあることだが),地域全体を覆うようなランダム点か格子点のpoint図形を発生させ,これを「生物がいなかった」地点として「生物がいた」地点の図形データと同じファイルに統合する.この場合は,地域全体の探索努力が均一であったか,あるいは地域全体を十分な努力量で調査して発見がすでに飽和しているのか,どちらかの仮定が必要である.また得られた予測地図での生物の出現確率は相対値となり,地域全体の中で相対的に多いか少ないかを表現するものになる.
3. 環境データを[属性値の計算]の諸機能を使って生物の分布のベクトル図形に読みとる.集計する距離を変えることにより,生物にとっての空間スケールを反映させることができる.土地利用図では[一定距離内の属性値の収集]において[頻度]を使うことにより,調査地点の周辺の一定距離内の土地利用タイプごとの面積をラスタのセル数として求めることができる.環境データを読みとった生物のベクトル図形の属性データには,生物の現存量や在・不在の変数と,環境変数が含まれている.
4. [属性値の計算とファイル統合]→[ベクトルファイルの統合]から統計ソフト用の外部ファイルができる.
5. この属性データを統計ソフトで解析する.生物の現存量や個体数,在・不在などを従属変数にして,多くの環境データを従属変数にして,重回帰,判別分析,ロジスティック回帰,決定木などの手法で予測モデルを作る.このとき予測モデルに取り込まれた環境変数は生物にとって重要な環境であると,おおむね考えることができる.
6. 地域全体を覆う格子点を発生させ,(a)の環境データを読みとる.上記の予測モデルを使って,このpointの環境から生物の在・不在や現存量を計算する.統計ソフトで行っても良いが,簡単なモデルなら[属性値の計算とファイル統合]→[ベクトル属性変数の演算]を利用できる.
7. この結果を画像に表示すると分布予測図ができる.ラスタファイルに変換してから表示すると高速.
8. GAP分析では,いくつかの重要な種の分布地図(多くの場合は上記のような予測図)と現在の保全地域を重ね合わせて,体系的かつ客観的に保全地域の見直しをおこなう.
9. この中でGISソフトが活躍するのは予測モデルから分布予測図を作るところである.調査地点の環境値の収集は,集水面積などのように環境値自体をGISで計算する必要があるとか,空間スケールを考えて集計するなどでなければ,紙の地図上でやっても野外調査の労力に比べればたいしたことではない.場合によってはGISソフトよりも良い統計ソフトのほうが重要かもしれない.
3.5 細切れに撮った写真や分割してスキャナ入力した画像を1枚に貼合わせる
1. それぞれの画像をラスタファイルに読み込む
2.
[属性値の計算とファイル統合]→[ラスタ変数の演算と統合]から行う場合には,
(a) 貼りあわせる全範囲を網羅する空のラスタファイルを作成する
(b)[ラスタ変数の演算と統合]で,そのファイルに切れぎれの画像のラスタファイルのred, green, blueの変数を[統合]してゆく.
3.
純粋な画像の場合は[画像ファイルに出力]の機能をつかって行うことも可能である.この場合は3原色の変数ごとに演算を繰り返す必要はなく,また途中の結果も見ることができる
(a)2枚の画像を不透過モードで,輝度絶対値として合成して,[画像をcsv保存]チェックボックスで新しいラスタファイルとして保存する.ファイル名はBMP画像ファイル名に.csvがつく.(画像1.bmp.csvなど)
(b)このラスタファイルに,さらに別の画像を合成する
(c)できた画像をBMPファイルに書き出す
(d)画像合成時にpixelサイズを頻繁に変更すると,単純なサンプリングが行われているため画質が劣化する.pixelサイズは固定しておく.
3.6 空中写真を使った植生のタイプ分け(自動分類)
1. 空中写真をラスタデータに読み込む
2. 適当なサンプリング密度で,プローブ用のpoint格子を生成する
3. 空中写真のラスタデータのred, green, blueの属性変数(光の波長のバンド)を,プローブ用のpoint格子の図形ファイルに収集する.季節の異なる写真を読み込んで変数を増やすこともできる.収集距離を大きくして標準偏差などの統計量を利用すれば,pixelの輝度値だけでなく周辺のテクスチャの情報を反映させることもできる.
4. [その他・応用プログラム]→[サンプルの自動分類]で自動分類する.
5. point格子ではいったんラスタファイルに変換したあと([かたちの情報の変換と計算]→[point属性を補間してラスタに]),WindowsビットマップのBMPファイルに出力する.
6.
好みの統計ソフトを使う場合には,
(a)エディタやExcelを使って,point格子の図形ファイルのヘッダの始めの2行(”vector”とコメント行)を削除する.
(b)できたCSVファイルを統計ソフトに読み込んで,好みの方法でタイプ分けする.
(c)結果をCSVファイルに戻し,先頭にヘッダを付け加える(”vector”とコメント行).データはひとつのテキストファイルの中だけに存在するので,解析で変数の数が増減してもかまわない.
(d)あるいは[属性値の計算とファイル統合]→[ベクトルファイルの統合]から外部ファイルに書き出し,統計ソフトで計算後におなじく[属性値の計算とファイル統合]→[ベクトルファイルの統合]でもとのファイルとマージしてもよいが,マージに処理時間がかかるのでエディタで編集した方が楽でかつ簡単でもある.
実例:ある地方都市の自動地被分類
1. 例4.5と同じ2km×4.5kmの範囲の分類を試みた.1:2500都市計画基図3枚と空中写真2枚分にかかっている.
2. 50m×50m間隔のpoint格子を使って,夏の空中写真からデータを抽出した.その地点の画素のred, green, blueの輝度,半径が10m, 31.6m, 100m, 316mの範囲のred, green, blueの輝度の最大,最小,平均,標準偏差,4分位(中央値を含む),最頻値,の99変数を抽出した.
3. [その他・応用プログラム]→[自動分類]でpointを自動分類.いちおうMDLを使用したが,単純な尤度でも同じ結果になると思われる.
4. 結果を50mメッシュのラスタファイルに継承させ,地図画像と重ねて出力した
5. 4グループ(同時2分割,2階層)の分類で,森林,耕地,農村集落,市街地・工事現場を分けることができた.
|
|
|
|
|
図3.1 地被の自動分類の例.このあとの例3.7と同じデータを使っている.上図は4グループ(同時2分割,2階層)に,下図は16グループ(同時2分割,4階層)に分割した結果. |
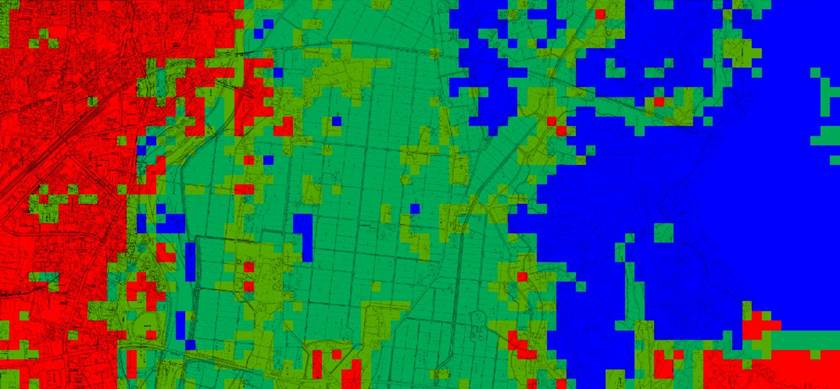
3.7 空中写真を使った地被のタイプ分け(トレーニングエリア)
1. 対象地域の地図上に座標系を設定し,対象地域の地図をラスタデータに取り込む
2. [データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]を使って,コントロールポイントに使える場所の座標を読んでおく(マウスをあわせると座標が表示される)
3. 上記のコントロールポイントを使って空中写真をラスタデータに読み込む
4. 空中写真のラスタデータを背景にしたマウスによる図形入力で,トレーニング領域をpolygonやareaとして指定し,その属性値として植生タイプを文字列で入れておく
5. 適当なサンプリング密度で,プローブ用のpoint格子を生成する
6. 空中写真のラスタデータのred,green,blueの属性変数(バンド)を,プローブ用のpoint格子の図形ファイルに収集する.季節や赤外線写真など波長域の異なる写真を読み込んで変数を増やすこともできる.集計距離を大きくすると景観の分類もできる.
7. トレーニング領域の属性値(植生タイプ)をプローブ用の格子図形のファイルに収集する.[文字列の最頻値]が便利.このファイルには「red冬,green冬,blue冬,red夏,green夏,blue夏,トレーニング植生タイプ」などの属性が含まれている.トレーニングエリア外のデータでは「トレーニング植生タイプ」は欠損値になっている
8. エディタやExcelを使って,この図形ファイルのヘッダの始めの2行(”vector”とコメント行)を削除する.
9. できたCSVファイルをSPSSなどの統計ソフトに読み込んで,各種の判別分析や,AnswerTreeなどの決定木解析を自由におこなってタイプ分けする.
10. 結果をCSVファイルに戻し,先頭にヘッダを付け加える(”vector”とコメント行).データはひとつのテキストファイルの中だけに存在するので,解析で変数の数が増減してもかまわない.あるいは[属性値の計算とファイル統合]→[ベクトルファイルの統合]から外部ファイルに書き出し,統計ソフトで計算後におなじく[属性値の計算とファイル統合]→[ベクトルファイルの統合]でもとのファイルとマージしてもよいが,マージに処理時間がかかるのでエディタで編集した方が楽でかつ簡単でもある.
11. BMPファイルに出力する.point格子ではいったんラスタファイルかpolygon格子に変換しておく.
実例:ある地方都市の教師つき地被分類
1. 2km×4.5kmの範囲の分類を試みた.1:2500都市計画基図3枚と空中写真2枚分にかかっている.
2. 50m×50m間隔のpoint格子を使って,夏の空中写真からデータを抽出した.その地点の画素のred, green, blueの輝度,半径が10m, 31.6m, 100m, 316mの範囲のred, green, blueの輝度の最大,最小,平均,標準偏差,4分位(中央値を含む),最頻値,の99変数を抽出した.
3. 森林,耕地・草地・河川敷,農村集落,都市,の4カテゴリでトレーニングエリアを設定した.
4. SPSS社のAnswerTree(http://www.spss.co.jp/)を用いてCHAIDによって決定木を作成し,このルールをSPSSのコマンドシンタックスに貼りこんで全体のpoint格子での地被を推定した.
5. 大きな空間スケールの統計量を使うことにより,都市の住宅地と農村の集落のような景観の違いを区別することができた.区分する変数としては広い空間スケールの統計量が選択された.4m, 10m, 31.6m, 100m, 316mの空間ケールの変数が区分に使われた頻度はそれぞれ0%, 4%, 26%, 39%, 30%であり,100mの空間スケールでの統計量が役立っていて,地点のRGB値は全く使われなかった.単一の画素のスペクトルからは庭木の樹冠と森林との区別は不可能なので当然の結果である.
6. 統計量のタイプでは,輝度の平均値や標準偏差などのパラメトリックな統計量よりも,4分位数(中央値を含む)や最大・最小値,最頻値などのノンパラメトリックな量が有効であった.平均・標準偏差,4分位・最頻値,最大・最小の3カテゴリに分けると,CHAIDで地被区分に利用された頻度はそれぞれ,22%, 48%, 30%であった.
7. 今回は密着の空中写真が利用できなかったので事務用のコピー機で複写したものを用いたが,できればフィルムの原版をスキャンするか,少なくとも密着焼きが望ましい.またjpegなどの情報を失う圧縮方式のファイルを経由することは望ましくない.
|
|
|
|
|
図3.2 トレーニングエリア(上)と分類された地被(下). 紫:市街地,黄色:農村の集落,緑:耕地・草地・河川敷,水色:森林 |
3.8 いくつかの地点で測定した気温のデータから地域全体の気温分布図を描く.あるいは測量結果からDEMをつくる.
1. 地点の正確な座標値がない場合は,地図の上に測定地点を書き込む
2. この地図をスキャナで読み込んで24bitカラーのWindowsビットマップの形式のファイルに保存し,さらに[データ入力編集・空の図形の発生]→[BMP画像ファイル→ラスタファイル]を使ってラスタファイルとしておく.
3. [データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]で地図を画面に表示して,観測地点をマウスでクリックしてpointの属性値として気温などの測定値を入れる
4. 分布図を保存するための,必要な地域をカバーした空のラスタファイルを生成させる.
5. [かたちの情報の変換と計算]→[point属性を補間してラスタに]にて[補間]オプションを使って補間されたラスタデータを作成
6. 必要に応じて[画像ファイルに出力]にて,元の地図画像に重ねて気温の分布を表示したBMPファイルを作成する
7. 不規則な地点の測量結果からDEMを作成する場合も同様の手順になる
3.9 等高線が描かれた紙の地形図からメッシュ高度データ(DEM)を作成する
1. 等高線が描かれた地図をスキャナで読み込んで24bitカラーのWindowsビットマップ画像ファイル(BMP)で保存し,さらに[データ入力編集・空の図形の発生]→[BMP画像ファイル→ラスタファイル]を使ってラスタファイルとしておく.
2. [データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]で地図を画面に表示して,等高線上の地点をマウスでクリックしてpointの属性値として標高を入れる.
3.
標高を入力する点として,少なくとも尾根線や谷線は押さえておく.また地形が急に変わる地点では「地形の曲がり方」を表現できるような位置にも観測点をおく.
あるいは尾根線や谷線上の等高線に加えて,格子線と等高線の交点を入力しても良いかもしれない.
4. 必要な地域をカバーしたプローブ用のラスタファイルを生成させる.
5. [かたちの情報の変換と計算]→[point属性を補間してラスタに]にて[補間]オプションを使って補間されたラスタデータを作成
6. [その他・応用プログラム]→[集水面積]から集水量を計算し,集水量を対数変換して画像として見るとデータ入力のミスをチェックするのに役立つ.
|
|
|
|
図3.3 地図画像上での高度入力(左)と作成したDEMを地形図画像に重ねたもの(右) |
|
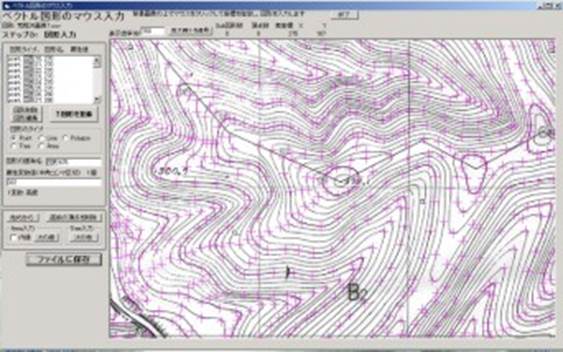
3.10 土地の傾斜の計算や,画像のエッジ検出など
1. [その他・応用プログラム]→[日射環境]や[集水面積と起伏]でも傾斜や斜面方位,ラプラシアンの計算ができるが,Excelで直接計算してみても良いかもしれない.このあたりの数式は大学の一般教養の微分・積分の教科書に載っていることが多い.
2. 標高データを含むラスタファイルをダブルクリックしてExcelなどで開く
3. 傾斜を保存する変数を作成する.データのはいるセルの範囲をわかりやすくするため,(a)ひとつの属性変数のプレーンを変数名を含めてファイルの最後にコピーし,(b)変数名を好みの変数に書き換え,(c)ファイル始めのヘッダの属性変数の数をひとつ増やし,(d)新しい属性変数のセルに欠損値として文字列のnullをコピーしておく.
4.
新しい属性変数について,近傍の高度から傾斜を計算する式をセルに入力して全域にコピーする.
<傾斜>
傾斜=ACOS(1/(x方向傾斜^2+y方向傾斜^2+1))
ただし,
x方向傾斜=(右セル−左セル)/(セルの横幅の実距離*2)
y方向傾斜=(上セル−下セル)/(セルの縦幅の実距離*2)
また,ACOSはコサインの逆関数.
<地形の凹凸,ラプラシアン>
ラプラシアン=(左セル+右セル−2*自セル)/セルの横幅の実距離+(上セル+下セル−2*自セル)/セルの縦幅の実距離
|
|
|
|
図3.4 図3.3のDEMを使ってExcelで計算した傾斜角度(左,色の濃いところが急傾斜)とラプラシアン(右,色の濃いところが凹地形).より高次の微分になるラプラシアンではノイズの影響を受けやすいため,1mメッシュで求めた後で半径5mの移動平均で平滑化した(平滑化は[属性値の計算とファイル統合]→[ラスタと図形の属性を集計してラスタへ]).またExcelでは残念ながら256列のデータしか扱えない. |
|
3.11 生物のマッピング結果から重要な地域を検出する
1. 重要な生態系に出現する指標種を抽出する
2. 野外調査で指標種をマッピングする
3. マッピングした地図をスキャナ入力し,ラスタファイルに取り込む
4. このラスタファイルを背景としながら,生物の分布域をマウスで図形入力する.pointやpolygonなどが混在してもかまわない.生物の種類を属性値とする(図26).
5. 地域の評価に必要な空間スケールで,地域全体をカバーする長方形polygon格子を生成する
6. [属性値の計算とファイル統合]→[一定距離内の図形やpixel属性を収集して図形に]を使って,生物分布の図形ファイルの「種名」属性値を,プローブ用のpolygon格子ファイルに取り込む.このとき距離はゼロとする.ここで[頻度]を指定することによって種名ごとの属性変数が生成され,格子内に存在する分布地の数がカウントされる.
7. Excelでpolygon格子ファイルを開き,もし格子内の種数で評価するならゼロ以外のところをカウントする式を使うことで(COUNTIF関数),格子ごとの種数を求める.種による重み付けなども可能.
8. 評価地域の白地図をスキャナ入力してラスタファイルにしておき,polygon格子ファイルを透過モードで白地図と合成し,BMPファイルに書き出す(図28).
9. 凡例などはlineやpolygonとして作成した.まず白地図に枠線を合成し,その上に種分布データと凡例を合成した.文字は後から写真レタッチソフトで入れた.
実例: 横浜国立大学常盤台キャンパス周辺の重要な植生の分布 (小池,田中,馬場,石井,五十嵐,小室)
横浜国大のキャンパスは丘陵の上にあり戦前からのゴルフ場の跡地だが,周辺は宅地化されている.キャンパスのまわりには,かつて畑の土手や明るい林の下に生育していた植物の生活する植生が断片的に残っている.学生実習のなかで,このような植生の分布を指標種のマッピングによって調べた.
植物社会学的な植生タイプを地図におとしても類似の結果になるが,今回の方法では,(a)高度な専門的知識は不要,(b)種の欠落の状況を定量的に評価できる,(c)調査の品質管理が容易,などの利点がある.
指標種として草原種のツリガネニンジンやクサボケなど,また雑木林種としてガマズミなどの,合計9種を使用した.1:2500地形図(横浜市では関内駅前の市役所で市販している)を使って,500m×500mの範囲を3.4km歩き回り(市街地1.5時間,田園地帯2時間,丘陵地3時間),ルートを記入しながら種のマッピングを行った.1.5km四方(2.25km2)のこの地図全体を調べるとすれば2.25人・日の労力になる.仮にこの方法で都市近郊の25km2程度の区市町村全体を調べると約25人・日となる.
|
vector |
|||||||
|
横浜国大の草原種・雑木林種マッピング 2000年10月 |
|||||||
|
種名$ |
type$ |
name$ |
NodeNum |
xy1 |
xy2 |
xy3 |
xy4 |
|
クサボケ |
polygon |
図形1 |
5 |
1002.2 |
1442.6 |
1022.6 |
1437.8 |
|
ツルボ |
point |
図形2 |
1 |
1008.6 |
1437.6 |
|
|
|
ガマズミ |
point |
図形20 |
1 |
1195.2 |
1190.4 |
|
|
|
ガマズミ |
point |
図形25 |
1 |
1346.4 |
1360.2 |
|
|
|
ツリガネニンジン |
point |
図形26 |
1 |
646 |
1072.2 |
|
|
|
ツリガネニンジン |
point |
図形28 |
1 |
680.2 |
1054.8 |
|
|
図3.5 マウスで入力した図形ファイルの一部
|
vector |
|||||||||||
|
横浜国大 草原種+雑木林種 2000年秋 |
|||||||||||
|
view |
種名$_クサボケ |
種名$_ツルボ |
種名$_ムラサキシキブ |
種名$_ガマズミ |
種名$_ツリガネニンジン |
種名$_ミツバツチグリ |
種名$_オトコエシ |
種名$_未調査地 |
type$ |
name$ |
NodeNum |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
polygon |
g1 |
4 |
|
1 |
1 |
3 |
1 |
1 |
0 |
0 |
0 |
0 |
polygon |
g11 |
4 |
|
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
polygon |
g12 |
4 |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
polygon |
g13 |
4 |
|
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
polygon |
g14 |
4 |
図3.6 100m×100mメッシュ内の生育場所数.「頻度」で集計した.一部の種は省略してある.始めの「view」という変数はpolygon格子生成時のダミーの変数なので削除可.
|
|
図3.7 横浜国大周辺の重要な地域(「みんなでGIS」の出力に写真レタッチソフトで文字を入れた).5種以上が集中する場所(ホットスポット)が3地点みつかった.いずれも大学西北側の大池通りの周辺の丘陵斜面である.2地点は大学のキャンパス内にあるが,そのうちの1地点は校舎新築にともなう樹木の移植によって破壊されつつある.図中の縮尺はもとのファイルのものなので,インターネットの画面で見ると違った縮尺になる.
|
vector |
|||||||||||||||
|
横浜国大 草原種+雑木林種 グラフ枠 |
|||||||||||||||
|
red |
green |
blue |
type$ |
name$ |
NodeNum |
x1 |
y1 |
x2 |
y2 |
x3 |
y3 |
x4 |
y4 |
x5 |
y5 |
|
0 |
0 |
0 |
line |
外枠 |
5 |
0 |
0 |
1500 |
0 |
1500 |
1500 |
0 |
1500 |
0 |
0 |
|
0 |
0 |
0 |
line |
スケール |
4 |
1550 |
120 |
1550 |
100 |
1750 |
100 |
1750 |
120 |
|
|
|
0 |
0 |
0 |
line |
未調査枠 |
5 |
1600 |
400 |
1700 |
400 |
1700 |
500 |
1600 |
500 |
1600 |
400 |
|
0 |
0 |
0 |
line |
種数枠 |
5 |
1600 |
700 |
1700 |
700 |
1700 |
1300 |
1600 |
1300 |
1600 |
700 |
図3.8 図3.7の枠線を描く図形ファイル.枠線の太さが凡例の輪郭の太さと違うため,別のファイルにした.
|
vector |
|||||||||||||||
|
横浜国大 草原種+雑木林種 2000年秋 |
|||||||||||||||
|
view |
種名$_クサボケ |
種名$_ツルボ |
種名$_ムラサキシキブ |
種名$_ガマズミ |
種名$_ツリガネニンジン |
種名$_ミツバツチグリ |
種名$_オトコエシ |
種名$_未調査地 |
出現種数 |
red |
green |
blue |
type$ |
name$ |
NodeNum |
|
|
|
|
|
|
|
|
|
|
|
240 |
200 |
255 |
polygon |
凡例未調査 |
4 |
|
|
|
|
|
|
|
|
|
|
6 |
0 |
100 |
50 |
polygon |
凡例6 |
4 |
|
|
|
|
|
|
|
|
|
|
5 |
42.5 |
125.8333 |
84.16667 |
polygon |
凡例5 |
4 |
|
|
|
|
|
|
|
|
|
|
4 |
85 |
151.6667 |
118.3333 |
polygon |
凡例4 |
4 |
|
|
|
|
|
|
|
|
|
|
3 |
127.5 |
177.5 |
152.5 |
polygon |
凡例3 |
4 |
|
|
|
|
|
|
|
|
|
|
2 |
170 |
203.3333 |
186.6667 |
polygon |
凡例2 |
4 |
|
|
|
|
|
|
|
|
|
|
1 |
212.5 |
229.1667 |
220.8333 |
polygon |
凡例1 |
4 |
|
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
212.5 |
229.1667 |
220.8333 |
polygon |
g99 |
4 |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
255 |
255 |
255 |
polygon |
g98 |
4 |
図3.9 図3.7の凡例(塗りつぶし,始め7行)とデータの一部(最後の2行).
なお,福島県原町市での市民参加による同様の調査のレポートが以下のサイトにある.
http://vege1.kan.ynu.ac.jp/haramachi/report2001/
3.12 干潟や湖沼の浮葉植物の分布を調べる
1. 野外で干潟の分布や面積を調べるには空中写真があれば都合がよいのだが,潮位が時々刻々変化するために干潟の水面上の面積も変わってしまい,既存の空中写真の中から都合の良いものを探すのは難しい.しかし,岸から撮影した写真を真上から見たものに変換することはできるので,この画像をつかって干潟や浮葉植物の分布を調べることができる.ヒツジグサやフトヒルムシロ,ジュンサイなどの浮葉植物の湖面上の分布も同じようにして調べることができる.
2. [データ入力編集・空の図形の発生]→[BMP画像ファイル→ラスタファイル]を選択
3. 画像のタイプとして[斜写真]を選択.水面の座標に対応した画素情報を含んだラスタファイルを作成する.水面を真上から見おろした画像になっている.
4. この画像の上に干潟や浮葉植物の外縁をpolygonで入力するか,画像の質が良ければ画像処理などで干潟や浮葉植物の分布を調べることができる.
5. [ラスタ変数の演算と統合]をつかって複数の写真を1枚に合成できる.写真の範囲にない欠損値の部分もデータが存在する別の画像で補うことができる.polygonで切り抜いたり貼りこんだりすることもできる.
6. ここでは多摩川河口の六郷水門の近くの干潟の分布を調べた.座標は1:2500都市計画地図(川崎市デジタル地形図2500と東京都デジタルマッピング地形図)の座標系を用いて,都市計画図の座標系の上に画像をマッピングした.
7. 堤防上から写した写真をもとに,手前の水門や鉄塔,対岸の水門などにコントロールポイントを設定した.高さがわかればビルの屋上等に設定しても良い.できれば,解析する干潟の周囲と内部にコントロールポイントがあればより正確になる.
8. 変換後の画像では遠い地点のpixelが引き延ばされるため,入力写真は高い解像度が必要である.今回はレンズ付きフィルム(写ルンです,スーパースリムAPS)を使用したが,レンズの性能が低いために変換結果が荒い画像になってしまった.また入力写真中でコントロールポイントを探し出すのも難しかった.このような解析のためには,大口径のレンズをつかって高解像度のフィルムで撮影することが望ましい.
9.
この方法で求めた干潟の分布を国土地理院の土地利用メッシュデータに加えることもできる.
(a)「細密数値情報(10mメッシュ土地利用)」を「みんなでGIS」のファイルに変換しておく
(b)干潟をpolygon入力.変数値は土地利用図のコードで空き番号の20などにしておく.[データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]
(c)土地利用メッシュデータと同じか,あるいはより細かなメッシュの,空のラスタファイルを作成.座標の範囲は干潟をカバーしていれば,土地利用データより狭くても良い.[データ入力編集・空の図形の発生]→[ラスタファイル作成]
(d)干潟polygonのベクトルの値をラスタに距離ゼロで集計.polygonにかかるところには設定したコード値(たとえば20)が,それ以外は欠損値が入ったラスタファイルができる. [属性値の計算とファイル統合]→[図形やセルを集計してラスタに]
(e)上記の値を優先させて,土地利用メッシュデータと統合する.上記のデータのうち欠損値やファイル外の部分には土地利用データがそのまま入り,干潟の部分にだけコード20が入る.[属性値の計算とファイル統合]→[ラスタ変数の演算と統合]
|
|
図3.10 もとの写真(上)と変換後の画像(下).上の写真の紫の十字はコントロールポイントである. 下の画像では左上に水門があり,上が堤防側で下が川の流心側. 干潟の部分は濃い灰色になっている.淡い白が水面で,左下と右上の純白の部分は写真に写っていなかった欠損部分である. 水面より高い部分は位置が不正確である(水門やオギなど). |
|
|


3.13 汚染物質の拡散予測
1. 野外に散布された汚染物質の水による拡散を予測する.ただし,汚染物質の土壌への吸着や分解,蒸発などはなく,降水によって地面を流される過程のみを考える.また経時的な変化はわからない.
2.
汚染物質の初期分布図をラスタデータとして作成する.ある範囲に均一に散布された場合には,
a.地図を背景画像として散布範囲をpolygon入力する.「汚染物質分布」というような名前の属性変数をひとつ作り,値として1m2あたりの散布量(不明なら1.0などの,ゼロや欠損値以外の数)を入れておく.[データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]
b. polygonの値をラスタ変数に写し取る.[属性値の計算とファイル統合]→[図形やセルを集計してラスタに]から,ラスタファイルとして地形データの入ったファイルを指定し,ベクトル図形ファイルとしてa.で作成したファイルを指定する.polygonから距離ゼロでの平均値を計算すると,標高データのメッシュと同じメッシュ上に汚染物質の量がマッピングされる.
3. [その他・応用プログラム]→[集水面積と起伏]から,「標高変数」に標高の変数を,「降水量」の変数に汚染物質分布の変数を指定する
4. [集水量]をチェックして[実行]
5. 地形データと同じファイルのCatchmentという変数に,メッシュを通過した汚染物質の総量が記録されている
6. 谷には汚染物質の流入量も多いが,水の流入も多いので濃度(相対的な影響量)は低くなるかもしれない.相対的な濃度を計算するには「汚染物質の総量」/「集水量」を求めればよい.いったん汚染物質のCatchmentを「汚染物質流下量」などと変名してから,[集水面積と起伏]機能で集水量分布を計算してこれを新しいCatchimentとし,[属性値の計算とファイル統合]→[ラスタ変数の統合と計算]機能で比を計算する.
|
|
|
図3.11 黄色の四角形の内部に均一に散布された汚染物質が降水によって拡散したと想定する.「汚染物質通過量」/「集水量」として相対的な濃度を示す.青が濃いところで濃度が高い.はじめの散布域内にも濃淡ができる. |
3.14 生育地保全のための集水域の重要度評価
1. 生物の成育地の上流の開発が生育地の悪化につながる場合がある.ここでは集水域内の相対的な重要度を,「自分のセルを通過して生育地に流入する水量」/「生育地に流入する全水量」の値で評価する.途中での水の浄化は考えられていない.
2. [データ入力編集・空の図形の発生]→[ラスタ画像上にベクトル入力]から地図を背景画像として生育地をpolygon入力する.「生育地」というような名前の属性変数をひとつ作り,値として1などのゼロや欠損値以外の数を入れておく.
3. polygonの値をラスタ変数に写し取る.[属性値の計算とファイル統合]→[ベクトルやラスタの値をラスタに]から,ラスタファイルとして地形データの入ったファイルを指定し,ベクトル図形ファイルとしてa.で作成したファイルを指定する.polygonから距離ゼロでの平均値を計算すると,標高データのメッシュと同じメッシュ上に生育地の分布がマッピングされる.
4. [その他・応用プログラム]→[集水面積と起伏]から,「標高変数」に標高の変数を,「重要度評価対象のセル」の変数に生育地分布の変数を指定する
5. [集水域の重要度]をチェックして[実行]
6. 地形データと同じファイルのImportanceという変数に重要度が記録されている
|
|
|
図3.12 青い4角形が生育地で,緑が濃いほど重要度が高い. |
3.15 GPSを使用して森林で樹木の位置をはかり,サイズ(胸高直径)を円の大きさで表現し,雌雄を色で表して,地図上に表示する
1. 樹木の座標(緯度.経度)とサイズなどが記録された外部ファイルを用意する.
2. [データ入力編集・空の図形の発生]→[地点の経緯度を一括変換]で平面直角座標(都市計画図,営林署1:5000図)やUTM(国土地理院1:25000地形図)のベクトルファイルに変換
3.
樹木のサイズを表す円形polygonをつくる
・円の中心座標(木の位置)を属性変数にもってくるため,[かたち情報の変換と計算]→[ベクトル図形の特性値]から地点のpoint図形の重心を計算する(Excelでコピーしても簡単だが).
・[かたち情報の変換と計算]→[円形polygon作成]で,中心点にCenterXとCenterYを指定し,半径に「胸高直径」を指定して(適当に倍数をかけておく),新しいベクトルファイルを作成.属性値は全て継承される.
4. [画像ファイルに出力]より,背景画像の上に樹木の円形polygonを表示する.雌雄などの情報を色で示す.
|
|
図3.13 円の直径が樹木のサイズをあらわし,色は樹木の雌雄を表す.探索ルートをlineで結んでいる.図2.5のデータを表示した. |
3.16 GPS測定地点からの距離と方位で植物のマッピングをしたとき
1. たとえば種子を付ける母樹の緯度・経度をGPSで測定し,実生の位置を母樹からの距離と方位(北から東へ時計回りに)を記録したとする.
2. 図に示すような先頭行に変数名を含んだCSVファイル(コンマ区切りのテキストファイル)を作成する.緯度や経度には全て対応する母樹の値を入れる.
3. [データ入力編集・空の図形の発生]→[地点の経緯度を一括変換]で平面直角座標(都市計画図,営林署1:5000図)やUTM(国土地理院1:25000地形図)のベクトルファイルに変換.このとき全ての実生は母樹の座標を持つ.
4. 母樹の位置(GPS測定地点の座標)を属性変数にもってくるため,[かたち情報の変換と計算]→[ベクトル図形の特性値]から地点のpoint図形の重心を計算する(Excelでコピーしても簡単だが).
5. [かたち情報の変換と計算]→[個々の図形の平行移動と回転]で,母樹(GPS測定地点)からの距離だけ,y軸方法に平行移動させる
6. 同じく[かたち情報の変換と計算]→[個々の図形の平行移動と回転]で,方位角(北から東回りの「度」)だけ,点(CenterX, CenterY)を中心に回転させる
7. これで,全ての個体の地図上の座標(平面直角座標やUTM)が得られている.地形図画像を背景にファイル出力し,間違いがないか確認する.
8. なお,ここでの「北」は地図上のy軸方向なので,磁石の北や真の北とはずれがある.磁石で方位を図った場合は,真の北とのずれと,地図に投影するときに生ずるずれ(平面直角座標やUTMではy軸方向は本当の北ではない)の,両方を補正しておく.後者は国土地理院のホームページ(http://vldb.gsi.go.jp/sokuchi/surveycalc/)で求めることができる.
|
Name$ |
母樹番号 |
緯度-度 |
緯度-分 |
緯度-秒 |
経度-度 |
経度-分 |
経度-秒 |
距離 |
方位 |
母樹実生 |
|
|
p1 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
0 |
0 |
母樹 |
|
|
p1-1 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
15 |
73 |
実生 |
|
|
p1-2 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
44 |
123 |
実生 |
|
|
p1-3 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
25 |
212 |
実生 |
|
|
p1-4 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
16 |
15 |
実生 |
|
|
p2 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
0 |
0 |
母樹 |
|
|
p2-1 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
19 |
20 |
実生 |
|
|
p2-2 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
40 |
239 |
実生 |
|
|
p3 |
3 |
30 |
21 |
32 |
130 |
23 |
15 |
0 |
0 |
母樹 |
|
|
p3-1 |
3 |
30 |
21 |
32 |
130 |
23 |
15 |
15 |
190 |
実生 |
|
|
|
図3.14 母樹(黒四角)でGPSにより緯度と経度を測定し,個々の実生は母樹からの距離と方位を測定した場合.
|
|
|||||||||

3.17 長方形の調査地の原点でGPSによって緯度と経度を計った
1. [その他・応用プログラム]→[ラインセンサスの座標計算]から計算しても良いが,[個々の図形の平行移動と回転]を使うと多くの調査地の座標計算を一括して行える.
2. 野外では,調査地(コドラート,プロット)の原点でGPSなどによる緯度・経度の測定を行う.また縦軸の方位を記録する(北から東回り(時計回り)に測定した「度」).なお,横軸は原点に立って縦軸に向かったときの右手側とする.
3. 図に示すような先頭行に変数名を含んだCSVファイル(コンマ区切りのテキストファイル)を作成する.緯度や経度には全て対応する原点の値を入れ,回転角は同一プロットでは全て同じ値を入れる.
4. [データ入力編集・空の図形の発生]→[地点の経緯度を一括変換]で平面直角座標(都市計画図,営林署1:5000図)やUTM(国土地理院1:25000地形図)のベクトルファイルに変換.このとき全ての樹木は原点の座標を持つ.
5. 原点の位置を属性変数にもってくるため,[かたち情報の変換と計算]→[ベクトル図形の特性値]から地点のpoint図形の重心を計算する(Excelでコピーしても簡単だが).
6. [かたち情報の変換と計算]→[個々の図形の平行移動と回転]で,横軸方向の座標だけx軸方向に,縦軸方向の座標だけy軸方向に平行移動させる
7. 同じく[かたち情報の変換と計算]→[個々の図形の平行移動と回転]で,縦軸の方位角(北から東回りの「度」)だけ,点(CenterX, CenterY)を中心に回転させる
8. これで,全ての個体の地図上の座標(平面直角座標やUTM)が得られている.地形図画像を背景にファイル出力し,間違いがないか確認する.
9. なお,ここでの「北」は地図上のy軸方向なので,磁石の北や真の北とはずれがある.磁石で方位を図った場合は,真の北とのずれと,地図に投影するときに生ずるずれ(平面直角座標やUTMではy軸方向は本当の北ではない)の,両方を補正しておく.後者は国土地理院のホームページ(http://vldb.gsi.go.jp/sokuchi/surveycalc/)で求めることができる.
|
Name$ |
プロット番号 |
緯度-度 |
緯度-分 |
緯度-秒 |
経度-度 |
経度-分 |
経度-秒 |
縦軸方位 |
横位置 |
縦位置 |
胸高直径 |
||
|
p1-1 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
15 |
9.74 |
7.17 |
12.5 |
||
|
p1-2 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
15 |
19.07 |
19 |
45.6 |
||
|
p1-3 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
15 |
15.01 |
14.51 |
13.6 |
||
|
p1-4 |
1 |
30 |
21 |
45 |
130 |
23 |
22 |
15 |
46.03 |
2.05 |
19.2 |
||
|
p2-1 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
230 |
1.56 |
10.6 |
22.3 |
||
|
p2-2 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
230 |
41.41 |
7.04 |
12.5 |
||
|
p2-3 |
2 |
30 |
21 |
40 |
130 |
23 |
15 |
230 |
15.43 |
17.7 |
11 |
||
|
|
図3.15 長方形の調査区(コドラート,プロット)で,原点からの縦・横の相対位置と,原点でのGPSでの緯度・経度の測定,縦軸の方位角の測定を行った.上の表のように,複数の調査区のデータを同時に変換できる.
|
||||||||||||

3.18 スクリーントーンを貼ったように見える地図の作製
植生などの領域がベクトルファイルのpolygonになっていて,これを投稿論文にするために白黒のスクリーントーンの模様で表現する場合は以下のようにする.
1. 地図の図郭にあわせて,好みの密度で長方形格子や格子pointなどを発生させる([データ入力編集・空の図形の発生]).
2. これを目的の画像の解像度と同じ解像度で画像ファイルに出力し,同時に画像をラスタファイルに保存しておく([画像ファイルに出力]で「画像をcsv保存」ボックスをチェック).スクリーントーンの画像のラスタファイルができる.
3. 植生などの領域を含むベクトルファイルは,目的の画像の解像度と同じ解像度のラスタファイルにしておく.[データ入力編集・空の図形の発生]で空のラスタファイルをつくり,[一定距離内の属性値を集計してラスタに]で集計距離ゼロを指定して「平均値」などを出しておく.
4. 目的の画像の解像度と同じ解像度の空のラスタファイルをつくっておき,これに画像データを作る[データ入力編集・空の図形の発生].
5. [ラスタ変数の統合と演算]で,データの値によってスクリーントーンの画像のラスタファイルを切り取り,ひとつのラスタ変数に統合してゆく.
6. できあがったラスタ変数を,赤・緑・青の3つに同時に入れて画像出力すると,モノクロの図ができる.
|
|
|
|



図.スクリーントーン(左)を切り取って(中),等高線に重ねる(右).
4.データ構造
空間的なデータの表現のしかたには,大きく分けて点や線,多角形などで表現するベクトル・ファイルと,画像などのように属性値を規則正しく並べたラスタ・ファイルの2種類がある.ちなみに画像もひとつずつの画素を4角形の図形として考えて,とても多数の4角形を含むベクトルファイルとして表現することもできる.ただし「半径50m以内の値の集計」というような空間的な処理をするばあいはラスタ・ファイルの方が速度が速い.
Excelなどでデータを直接操作することがない場合は,この章をスキップしてもかまわない.
4.1 ベクトル・ファイル(図形)
さまざまなタイプの図形をひとつのファイルに混在させることができる.ファイルの例は以下のとおり(図2).
|
コメントの文 変数名1, 変数名2, type$, name$, nodenum, a1,a2,a3,a4,a5,a6,a7,a8,a9,a10 変数値1, 変数値2,point,p2,1,8,17 変数値1, 変数値2,line,l2,5,8,20,13,20,13,15,8,15,8,20 変数値1, 変数値2,polygon,g3,4,8,20,13,20,13,15,8,15 |
図4.1 ベクトルファイルの例.
この一部をExcelで見ると以下のようになる.
|
vector |
||||||||||||||
|
コメントの文 |
||||||||||||||
|
変数名1 |
変数名2 |
type$ |
name$ |
nodenum |
a1 |
a2 |
a3 |
a4 |
a5 |
a6 |
a7 |
a8 |
a9 |
a10 |
|
変数値1 |
変数値2 |
point |
p2 |
1 |
8 |
17 |
|
|
|
|
|
|
|
|
|
変数値1 |
変数値2 |
line |
l2 |
5 |
8 |
20 |
13 |
20 |
13 |
15 |
8 |
15 |
8 |
20 |
|
変数値1 |
変数値2 |
polygon |
g3 |
4 |
8 |
20 |
13 |
20 |
13 |
15 |
8 |
15 |
|
|
図4.2 ベクトルファイルの例.網掛け部分はファイルのヘッダ.それ以降は1行がひとつの図形に対応する.文字がオレンジ部分は属性値関係で,文字が緑部分は図形の形状関係.
ヘッダ部
第1行のvectorはファイルのタイプを示す.固定値.
第2行はコメントの文章を入れる.長さは自由.ただし半角のコンマは使えない.
第3行は変数名を示す.このうち始めに属性変数名が入る.属性変数は自由に名前を付けられる.文字列変数では変数名の後に$文字をつける.ただしtype$などのキーワードやデータ区切りの半角コンマは使えない.属性変数は上限としてはいくつあっても良いが,最低ひとつは必要.その後に図形の形状に関する変数の変数名のtype$, name$, nodenum がはいる.この3変数の名前は固定である.type$は図形のタイプ名を, name$は図形の固有名称を, nodenumは,point, line, polygonなどの単純な図形では頂点数をあらわし,areaやtreeなどの複合図形では,含まれる単純な図形の数(areaを構成するpolygon数やtreeを構成するline数)を表す.pointやpolygonなど図形のタイプ名は必ず半角小文字を使う. a1からa10までは図形の座標値などであり,変数名は自由につけられるが(漢字も可),ファイル内の最長の図形データの最後尾のカラムに相当するところまで変数名を入れる必要があり,かつ変数名がそれ以上の個数あってはならない.
point
点を表す.type$はpoint,nodenumは必ず1になる.a1とa2には点のx座標(横)とy座標(縦)が入る.生物の個体が見つかった地点や,気象観測地点などにはこれを使う.
line
折れ線を表す.type$はline,nodenumは折れ線のノード数(両端を含む)になる.a1,a2以降はノード点の座標を連続して入れる.3つの点(x1, y1), (x2, y2), (x3, y3)を結んだ折れ線では,x1, y1, x2, y2, x3, y3 となる.畦畔や林縁など線状に分布する場合にはこれを使う.
polygon
多角形の内側を表す.凸でも凹でもよいが,辺どうしが交差してはいけない.type$はpolygon,nodenumは多角形の頂点数になる.a1,a2以降は頂点の座標を連続して入れる.3つの頂点(x1, y1), (x2, y2), (x3, y3)を結んだ三角形では,x1, y1, x2, y2, x3, y3 となる.元に戻って(x1, y1)を再度入力する必要はない.生育地が面的に広がっている場合などに使う.
area
複数のpolygonを内側か外側の外縁とし,これによって囲まれる領域を表す.ドーナツ状の領域や飛び地を表現できない.凸でも凹でもよいが,辺どうしが交差してはいけない.type$はarea,nodenumは構成するpolygon数になる.以下に例を示す.青字部分はキーワードである.
area, 名称, m, out,n1,x1,y1,x2,y2,x3,y3,in,n2,x4,y4,x5,y5,x6,y6
この例では,図形の固有名は「名称」,これを構成するpolygon数はm(ここでは2)である.次の「out」は最初のpolygonが領域の外縁であることを示すキーワードで,この頂点数はn1(ここでは3)で(x1,y1), (x2,y2), (x3,y3)の三角形となる.次のpolygonは「in」のキーワードで示されように領域の内側(ドーナツの内側の縁)であり,頂点数はn2(ここでは3)で(x4,y4), (x5,y5), (x6,y6)の三角形となる.現時点では領域定義の矛盾(inのpolygonが外にある状態など)はチェックしていない.
プログラム内部ではふつうのpolygonも,1つのpolygonで外縁(out)を決められたareaとして表現している.逆にあるpolygonの内部以外の無限の広さを持つ領域を表現するには,そのpolygonで内縁(in)を決められたareaとして表現する.ただし外縁が制限されていないareaは印刷時にうまく出力できないため(外側を囲む四角形の内側だけ塗りつぶされる),きれいに印刷するためには印刷領域(調査対象の地域)を全て包含する外縁のpolygonをこのarea図形に統合しておく([入力・編集]→[ベクトル図形のタイプ変更]).面積の計算では,外縁が制限されていないareaの面積はマイナスになって, ∞−a = ∞ のうちの−a のところだけが出力される.
tree
複数のlineによって構成される樹様の図形を表す.主に河川を表現することを想定している.type$はtree,Nodenumは構成する折線(line)の数になる.以下に例を示す.青字部分はキーワードである.
tree, 名称, m, root,n1,x1,y1,x2,y2,x3,y3,connect b2,n2,x4,y4,x5,y5,x6,y6
この例では,図形の固有名は「名称」,これを構成するline数はm(ここでは2)である.次の「root」は最初のlineが木の幹(川の主流)であることを示すキーワードで,このlineのノード数はn1(ここでは3)で(x1,y1), (x2,y2), (x3,y3)を結ぶ折線である.次のlineの「connect b2」はこのlineがb2番目のノードに合流することを示す.ノードの番号はこのデータの行の始めのノードから順に数える.このlineのノード数はn2(ここでは3)で(x4,y4), (x5,y5), (x6,y6)を通る折線となる.ここで(x4,y4)はb2番目のノードと同じ座標である必要がある.そうでなければ枝が幹から離れた図形になる(暗渠の場合?).現時点では矛盾(幹から離れた枝や自分自身への接続など)はチェックしていない.プログラム内部ではlineも構成線分数が1本のtreeとして表現している.
4.2 ラスタ・ファイル(画像・メッシュ値)
ファイルの例は以下のとおり.
|
raster コメントの文 variables,2 x,4,0,20 y,5,0,25 変数名1 5,10,15,20 4,8,12,16 3,6,9,12 2,4,6,8 1,2,3,4 変数名2 6,2,15,20 4,8,12,16 3,6,1,12 2,4,6,8 9,2,9,4 |
図4.3 ラスタファイルの例.
この一部をExcelで見ると以下のようになる.
|
raster |
|||
|
コメントの文 |
|||
|
variables |
2 |
|
|
|
x |
4 |
0 |
20 |
|
y |
5 |
0 |
25 |
|
変数名1 |
|
|
|
|
5 |
10 |
15 |
20 |
|
4 |
8 |
12 |
16 |
|
3 |
6 |
9 |
12 |
|
2 |
4 |
6 |
8 |
|
1 |
2 |
3 |
4 |
|
変数名2 |
|
|
|
|
6 |
2 |
15 |
20 |
|
4 |
8 |
12 |
16 |
|
3 |
6 |
1 |
12 |
|
2 |
4 |
6 |
8 |
|
9 |
2 |
9 |
4 |
図4.4 ラスタファイルの例.網掛け部分はファイルのヘッダ.それ以降はオレンジの文字の部分と赤い字の部分がそれぞれの属性変数(2枚のプレーンがある).文字が青の部分はキーワード.
第1行のrasterはファイルのタイプを示す.固定値.
第2行はコメントの文章を入れる.長さは自由.ただし半角のコンマは使えない.
第3行は属性変数の数を示す.ここでは2変数.属性変数は上限としてはいくつあっても良いが,最低ひとつは必要.
第4行は横軸方向での領域の定義であり,3つの数字はそれぞれ,横方向のセル(画素,pixel)数,左端のx座標値,右端のx座標値を示す.
第5行は縦軸方向での領域の定義であり,3つの数字はそれぞれ,縦方向のセル数,下端のy座標値,上端のy座標値を示す.
第6行は始めの属性変数の変数名で,属性変数は自由に名前を付けられるが(半角コンマは使えない),文字列変数では変数名の後に$文字をつける.
第7行以降は,セル(画像の場合は画素,pixel)の属性値を実際の画像の見た目と同じようにマトリックス状におく.始めの行は縦軸yの値が最も大きなところのセルで,最後の行は縦軸yの値が小さな場所のセルである(パソコンの画面の座標系とは上下が逆になる).行の中では,左側の値がx座標の小さなセルで,右端にある値はもっともx座標の大きな場所の値である. この例ではオレンジの字の部分と赤字の部分の2枚のプレーンがある.
画像を取り込んだ場合はred, green, blueの3変数の3つのプレーンがつくられる.この場合の変数名は固定したほうがよい.
5.空中写真や地図の入手先,情報源など
国土交通省の国土数値情報ダウンロード(https://nlftp.mlit.go.jp/ksj/index.html)や国土地理院の基盤地図情報ダウンロードサービス(https://fgd.gsi.go.jp/download/menu.php)から無料でダウンロードできる.標高は両サイトで異なるタイプのXMLデータを提供しているが,ここでは国土地理院のものに対応している.
日本地図センターでは国土地理院の1:25000地形図や土地利用図などさまざまな地図データと空中写真を販売している. http://www.jmc.or.jp/.
1:2500地形図(都市計画基図)は南北3km×東西4kmの地域を,縦120cm×横160cmの紙の上に表現している.全国一律のフォーマットでつくられていて,民家や田畑のあるところはほぼカバーしているが,山地では作成されていない場所もある.横浜市などでは市役所にて1枚700円で市販しているが,市販していない地域でも市町村役場でコピーさせてもらえるはずである(大きなコピー機が必要なので市中のコピー店では1枚のコピーに約1000円かかる).法律で決められた直交座標系(平面直角座標)であるため,本ソフトとの相性がよい.全国を19の地域に分けて座標系を定めてあり,関東平野は全体がひとつの座標系に属する.ふつうは図面の四隅にこの座標値をkm単位で表示してある.自分で歩いて地域の自然を調べるにはこの地図がよい.大きな地図なので500m×500m(地図は20cm×20cm)に切るとA4サイズ収まり取り扱いが楽である.なお1:2500地形図(都市計画基図)が無い地域でも国有林では1:5000地形図が整備されていて担当の森林管理署が有償で配布している.
国土地理院からは1万分の1地形図も市販されていて,座標系も都市計画図と同じであり(図の周りに座標値がkm単位で表示してある),上記の地図よりも少し大きなスケールの自然を調べるのに都合がよいが,惜しむらくは大都市周辺のごく一部の地域でしか利用できない.
最新の1:25000現存植生図の画像は環境省生物多様性センターのサイトで試験公開されている.http://www.vegetation.jp/
空中写真は,市街地は日本地図センターにあるが,山地は日本林業技術協会(http://www.jade.dti.ne.jp/~jafta/)で入手できる.なお神奈川県庁では全域の空中写真を県民向けに提供していて,コピーもできる.
その他,メッシュ地図をデータとして市販している会社も多い.
都市計画図などの大判の地図の取り込みは,A4サイズに切って自分のスキャナで入力して,このソフトでつないでも良いが,キンコーズ(https://www.kinkos.co.jp/)など町のプリントショップでスキャナ入力してもらうとたいへん簡単である.
集水面積などの解析の中身については,英語の本で専門的ではあるがTerrain Analysis (Wilson & Gallant著,John Wiley & Sons社,2000年)は良い教科書である.
日本地図センター発行の「数値地図ユーザーズガイド」(第2版補訂版)は少し専門的だが,各種の数値地図の説明に加えて,緯度経度から平面直角座標への変換プログラム例や,ベクトル図形とラスタの計算,鳥瞰図の作成プログラム例なども載っていてとても有益な情報源である.ただし緯度経度から平面直角座標への変換プログラムは10m程度の誤差を生ずることがわかったため,このプログラムでは座標変換に小林・上野著「ポケコンプログラムによる測量計算法」のものをVisual Basic用に改変して利用している。
なお緯度経度から平面直角座標への変換や日本測地系と世界測地系の相互変換は国土地理院のサイトhttp://vldb.gsi.go.jp/sokuchi/surveycalc/でもできる.ただしxとyがこのソフトとは逆になっているので注意が必要.(このソフトでは北がyで東がxだが,普通の平面直角座標は北がxで東がyで,裏返しになっているため座標軸を回転しても重ねることができない).2002年4月から採用された世界測地系をめぐる座標変換については「世界測地系と座標変換」(飛田著,日本測量協会)が大変わかりやすく,参考になる.
中波ビーコンで補正を行うGPSは,地形が尾根であれば携帯電話が使えないような山中の照葉樹林の林冠下でも1m程度の精度で座標を決めることができるので,ラインセンサスの起点の座標を知る場合などには便利である.ただし急峻な谷地形では難しい.(たとえばhttp://www.sokkia.co.jp/products/r80d.htm)
なお植物の生態を調べる立場から見ると,市販の地図データをそのまま利用できるのは下の図の50m(場合によって10m)より大きな空間スケールであり,気候データを利用できるのは1km以上の空間スケールである.実際の研究では自分で測量したり,1:2500都市計画基図から自分でDEMをおこす必要のある場合も多い.
|
|

図5.1 自然の空間スケールと人間社会の空間スケール,それに対応して利用できる地図データ.
6.謝辞
兵庫県人と自然の博物館の三橋氏にはTerrain Analysisの教科書を教えて頂きました.統計数理研究所の江口氏からは自動分類(座標付け分割法)について,また国土地理院の田辺氏からは緯度・経度から平面直角座標への変換プログラムについてアドバイスをいただきました.感謝いたします.
7.Q&A
Q1: 24bitのBMPフォーマットの画像を読もうとすると「サイズがへん」とのメッセージが出る
A: 原因はファイルのヘッダのパラメータが間違っていることによる.メッセージが出ても実際の処理には関係ない場合が多いと思うが,気になるのであれば,対策としてはWindows標準のペイントブラシで読みこみ,「左右反転」を2回繰り返すなど画像が劣化しない変更を加え,書き戻す.単に読んで書き戻すだけでは,読み込んだときのヘッダのパラメータをチェックせずにそのまま書き込んでしまうようだ. ソフトによっては書き込むBMPファイルのヘッダの内容が不正のものがある(アドビ社のPhotoshopなど?).いっぽうで読み込むソフトにも厳格なものと,ヘッダの内容に多少の矛盾があっても読んでしまうものがあり,マイクロソフト社のアプリケーションの間でもチェックの厳密さに違いがある.(このエラーメッセージは出さないようにしました.2003年3月)
Q2: ArcViewでポリゴンを入力してしまったが「みんなでGIS」の機能を使って解析や表示を行いたい.また国土交通省のDMフォーマットのデータを利用したい.
A: ArcViewのshapeファイルや国土交通省DMフォーマットを読込むプログラムの作成の優先順位は低いので,今後2年以内に実現することはなさそうだ.ポリゴンのデータは再入力していただくことになるが,ArcViewの属性データはdBASEのフォーマットであるため(拡張子.dbf),Excelにドラッグ&ドロップして読み込んでからポリゴンのデータと合体できる.なお,ライセンスの問題や将来のプログラミング環境の変化を考えて,shapeファイルやDMフォーマットを読込むための市販のOCXコンポーネントの利用はいまのところ考えていない.
Q3: 2002年4月からの世界測地系への移行にはどのように対応するのか
A: 2003年3月版から日本測地系(旧)と世界測地系(日本測地系2000)のどちらかが使えるようになった.経緯度電卓や緯度経度から平面直角座標やUTMへの座標変換プログラムでは以下の選択ができる.
日本測地系の経緯度 → 日本測地系の平面直角座標かベッセル楕円体のUTM
世界測地系の経緯度 → 世界測地系の平面直角座標かGRS80楕円体のUTM
世界測地系の経緯度(GPSなど)から日本測地系の経緯度への変換は,国土地理院のサイトでできる(http://vldb.gsi.go.jp/sokuchi/surveycalc/).なお,測地系によって,同じ地点であっても平面直角座標や地域メッシュ番号が変化する.このため研究プロジェクトごとに座標系をそろえておく必要がある.
いま入手できる印刷された地図はほとんどすべて日本測地系のものなので,当面は日本測地系(旧)を利用するのが良いかもしれない.ただし外部のデータを取り込むとき以外は,内部での解析や自分で測量した結果を解析するだけであれば測地系の違いは関係ない.
日本測地系と世界測地系の平面直角座標の間の変換は,数km程度の範囲の狭い地域であれば,平面直角座標の平行移動で変換してもかまわない.国土地理院のサイトを利用して,調査地域の中心と周辺四隅などで日本測地系と世界測地系の両方で平面直角座標を計算し,座標軸の平行移動の量を計算する.地域内での平行移動の差が許容精度の範囲内なら平行移動すればよい.
なお,世界測地系の「細密数値情報(10mメッシュ土地利用)」を購入して日本測地系のデータにあわせるためには,[かたち情報の変換と計算]→[座標軸の平行移動と回転]にて以下のパラメータで平行移動を行う. 首都圏では新しい座標系(日本測地系)の上での変換前(世界測地系)の座標系の原点はx=290m, y=−360m,中部圏ではx=270m,y=−350m,近畿圏ではy=−350m,x=260m.これは日本地図センターの変換ソフトTDConvの逆変換にあたる(http://www.jmc.or.jp/dl/10m/V12.html).
Q4: 国土地理院の50mメッシュの標高データを10mメッシュで補間したラスタファイルを作成し,大きなWindowsビットマップのファイルに書き出したら,段彩のような階段状の色濃度で表示された.
A: 表示だけの問題なので心配ない(Visual BasicのランタイムかWindowsのバグ?).データはなめらかに補間されているし,Photoshop LEなどで読み込めば正しく表示される.
Q5: 「みんなでGIS」は,ワードなどのWindowsのほかのソフトとは見た目が違うが,標準のスタイルにあわせる予定はあるか.
A: ワープロや表計算,作図などのソフトのWindows標準のスタイルでは,操作対象のファイルを表示したうえで[ファイル]や[編集]などのプルダウンメニューから操作を行う.これは (1)頻繁に利用して操作法を熟知し,(2)キーボードやマウスからのデータ入力が操作の中心である作業のためのものである.しかしGISの処理では複数のファイル間の操作が多く,ソフトの使用頻度も高くない.プルダウンメニューでは操作全体の流れがわかりにくい欠点もある(ウィザードで補っている場合も多い).ここでは,なるべくひとつのフォームに操作の流れ全体を示し,また操作方法の説明も可能な限りフォーム上に直接書き込むようにしている.
Q6: かたまってしまって動かない...
A: VisualBasicの普通のプログラムなので固まって動かないこと(ハングアップ)は基本的にない.表示を出さないで作業していることが多いと思う.大きなファイルを扱う場合は,タスクマネジャを常に起動しておいて(Windowsのタスクバーを右クリック)CPUやメモリの利用状況をモニタすることをすすめる.データの大きさによっては時間がかかりすぎて実質的に不可能な作業もあるので,オプションの見直しや,同じ処理内容を実現するためのやりかたの見直し(格子状polygonのタイルでなくラスタにするなど)が必要なこともある.
Q7: ファイル読み込み時に「〜番目のデータが正しくありません」とメッセージが出る.VectorFileSize.logを見るとデータのある行より先を読もうとしているが,Excelで見ても何も見えない.
A: ExcelでCSVファイルを編集して保存する場合に,範囲選択後に[Delete]キーを押して削除してCSVファイルに保存したときと,範囲選択後にメニューから[編集]→[削除]として削除してCSVファイルに保存したときとで動作が異なる.後者のやり方がよい.前者ではコンマ”,”だけがたくさん入った空の行ができてトラブルのもとになる.
Q8: 世界測地系の国土地理院の50mメッシュの標高データのCDを読もうとすると異常終了する.世界測地系の「細密数値情報(10mメッシュ土地利用)」も読めない.
A: 2002年に世界測地系に変わってからファイルのフォーマットやファイル名の付け方などが変更されていることがわかったので対応した.
Q9: CD-ROMの1:2万5千地形図画像をラスタに読みこめない.
A: 画素数が多いためそのまま(約2.5mの画素サイズ)ではメモリー不足になるので1/2解像度(5m程度の画素サイズ)で読み込む.また精度が高いはずなのにコントロールポイントの位置などによって誤差が100pixelを超えるようなことが起きる.このような場合は「ゆらぎ」チェックボックスをチェックして変換パラメータを求めると良い.
8.プログラムの改訂履歴
2022年3月16日 中央値のブートストラップ検定を追加.
2021年10月13日 画像上のベクトルファイル入力でノード順を逆にした新図形を作成する機能を追加.
2021年7月11日 ラスターファイルをタイルpolygonのベクトルファイルに変換する機能を追加.画素×変数のテーブルと,(変数名,編数値)によるリストを選択できる.
2021年5月25日 不具合の修正
2021年2月24日 標準地域メッシュで座標を指定されたcsvファイルを読込む機能を追加.
2020年12月28日 土地利用や標高などXMLファイル(GML)によるメッシュデータ読み込み機能を追加.
2019年11月17日 DXFファイル読み込み機能を追加.
2019年8月2日 polygon間の距離計算の不具合を修正
2019年6月21日 画像をpixel座標で直接読み込む機能などを追加.
2016年12月14日 不具合の修正(圧縮ファイル不調など)
2016年12月6日 さまざまなトラブル対策(最大化されたフォームでの異常終了,画像ファイル読み込みでの座標消失),新機能の追加
2015年2月1日 提供サーバーを移転
2015年1月9日 同一地点で重複測定したデータをリストに変換する機能を追加
2013年10月8日 生息地への個体の配属機能を追加
2012年11月19日 画像読込での精度向上
2012年1月28日 ダウンロードするファイルを自己解凍の実行ファイルからzipファイルに変更.「個体群の拡大過程」に環境を積タイプで指定できる機能を追加
2011年9月14日 「図形間距離の尤度分布から地図再構築」,「頻度からの尤度による傾度分析」,「一対比較による傾度分析」を追加.
2010年6月13日 分布拡大パターン解析の修正
2010年6月11日 属性値をベクトルに集計する機能の不具合修正
2010年5月10日 各種の不具合修正.個体群拡大過程でパラメータのランダム選択機能を追加.
2010年4月27日 各種の不具合修正
2010年3月24日 ベクトルファイルの表(たとえば地点×種名の表に優占度が入る)をリスト(地点,種名,優占度)に変換する機能を追加
2009年9月4日 ベクトルファイルのリスト(たとえば地点,種名,優占度)を表(地点×種名の表に優占度が入る)に変換する機能を追加
2009年5月19日 「個体群の拡大過程(メタ個体群のシミュレーション)」に積タイプの移住関数を追加
2009年4月23日 不均一な環境での到達時間距離の不具合再修正
2009年3月12日 若干の仕様変更・不具合修正など
2009年1月22日 ベクトル図形のタイプ変更(lineやtreeを等しい長さの多数のlineに分割する機能)の不具合を修正
2009年1月22日 lineやtreeを等しい長さの多数のlineに分割する機能などを追加
2009年1月19日 画像の四隅の経緯度を指定して任意の投影方法の画像を直接ラスタファイルに読み込む機能を追加
2008年8月1日 領域の統合型クラスター回帰を行う機能を追加
2008年3月31日 「BMP画像のGISラスタファイルへの変換」と四隅の緯度・経度を指定した「古地図入力」で,画像の任意の位置を中心部に表示させる機能を追加
2008年3月28日 画像を背景にしたベクトル図形入力で,画像の任意の位置を中心部に表示させる機能を追加
2008年3月23日 area図形で飛び地も扱えるように改良.「個体群の拡大過程(メタ個体群のシミュレーション)」に若干の機能追加
2008年3月11日 「個体群の拡大過程(メタ個体群のシミュレーション)」にさまざまな距離を扱うことができる機能を追加
2008年3月6日 外来生物の侵入順序を解析して統計的に分布拡大を予測する機能を追加.
2008年3月5日 不均一な環境での図形間の到達時間距離を求める機能を追加.
2008年2月29日 「BMP画像ファイルの読込」で縮尺の小さな地図では「ポイントが重なっている」として作業を停止してしまう不具合の修正.
2006年12月16日 「属性変数を集計して図形に付与」に属性変数の値によってグループ分けして統計量を計算する機能を追加.また4分位数や最頻値の不具合修正.
2006年6月27日 2万5千分の1地図画像CDの濃い色を紙地図に近い背景用の色に変換する機能を追加.
2006年5月31日 [ベクトルファイルの統合]に,属性値をキーにして複数の図形に1対多の属性値のマージを行う機能を追加.図形を指定数だけコピーする機能を[かたちの情報の変換と計算]に移動.
2006年2月24日 図形を属性値で指定した数だけコピーする機能を追加.画像上のベクトル入力で,属性入力ボックスにてEnterキーや↓キーで図形登録可能になった.
2005年8月25日 [集水面積と起伏の計算]での集水面積,比集水面積,集水域重要度の不具合を修正([その他・応用プログラム]).2005年1月6日から2005年7月20日までの版を使った場合は再計算をお願いします.
2005年7月20日 画像のラスタ読み込みの改良.
2005年7月9日 折線lineを多数の単線分lineに分解する機能を追加し画像出力高速化.
2005年5月17日 世界測地系の「数値地図50mメッシュ標高」に対応.
2005年4月30日 世界測地系の「細密数値情報(10mメッシュ土地利用)」に対応.
2005年3月31日 種子散布カーネルを求める機能を追加[その他・応用プログラム].高速版の実行ファイルを提供
2005年1月21日 画像入出力の高速化
2005年1月6日 投影パラメータ不明の古い地形図を読み込む機能を追加(データ入力編集・図形の発生).[集水面積と起伏の計算]で比集水面積とメッシュの集水面積を選択して計算できる機能([その他・応用プログラム]).その他のデフォルト設定の変更など.
2004年8月26日 外来種の最適駆除戦略のためのプログラムを追加([その他・応用プログラム])
2004年3月31日 ロジスティック回帰を行う機能を追加([その他・応用プログラム])
2004年3月24日 [画像上でベクトル入力]の[編集]で属性データが壊れる不具合を修正
2004年3月18日 マニュアルにインストール時の注意事項を記載.(WindowsXPを含めたSETUPの必要性,インストール時のユーザー名に2バイト文字不可,など)
2004年3月16日 図形(サンプル)を乱数で再サンプリングする機能と,図形間の距離計算で受け側と相手側のファイルが異なる場合に「飛び石距離」を計算する機能を追加.
2004年3月4日 野外でGPSから座標を読み込む機能を追加([経緯度電卓]および[画像上でベクトル入力]).不具合の修正(パソコンの機種等による表示の乱れ).これ以後のバージョンはRS-232CをつかうためのMSCOMM32.OCXが必要なので,改めて新しいファイルをダウンロードしてSETUPプログラムによるインストール作業を行ってください.
2004年2月3日 無料でダウンロードできる全国の植生調査3次メッシュデータ(約1kmメッシュ)を読み込む機能を追加.
2004年1月29日 無料でダウンロードできる数値地図2500(空間データ基盤)を読み込む機能を追加.1:2500都市計画図相当の市区町村,町丁目,道路,鉄道,河川等.
2004年1月4日 不具合の修正(ベクトルファイルのマージでの属性データの消失,polygonの内外反転での異常終了)
2003年12月12日 集水面積の計算でメモリーの振分を指定できるようにして,止水域の多い地形と少ない地形に対応した.
2003年10月28日 「ベクトル図形のマウス入力」のファイル保存等の不具合の修正.
2003年10月17日 10mメッシュ土地利用データの広域の集計機能を追加(首都圏のみ).
2003年10月14日 地図などの画像読込の不具合を修正,集水域計算でより止水域数の多い地形に対応.
2003年9月29日 個々のベクトル図形を別々に移動・回転させる機能を追加.
2003年9月26日 GPSなどによる地点の緯度・経度座標の一括変換機能,統計用にランダム点を発生させる機能,画像ファイル出力時に空間範囲や解像度を一時的に保存できる機能,をそれぞれ追加.
2003年7月28日 世界地形データGTOPO30を読み込む機能を追加,メタ個体群シミュレーションでパッチごとの絶滅確率を属性変数として与える機能を追加,UTM座標が計算できない不具合の修正.
2003年6月8日 WindowsXP用の配布セット作成
2003年5月8日 不具合の修正(「ベクトル図形のマウス入力」のコピー,「サンプルの自動分類」の異常終了,「ベクトル図形のタイプ変更」,「図形間の距離」)
2003年3月26日 属性値を中心座標や半径とする円形のpolygonやpointを作成する機能を追加.
2003年3月24日 世界測地系に対応.その他の不具合を修正(多角形の面積,ベクトルファイルのマージ,など)
2002年9月2日 自動分類で個別分布に等しい標準偏差を仮定できるオプションを追加.データ数が少ない場合に1サンプルだけを区分できる
2002年6月26日 メニューの編成を変更.等値線や多角形領域を取得する機能を追加. その他の機能追加と不具合の修正
2002年4月11日 集水面積計算,ラインセンサスの座標計算,最大値回帰の機能を追加.緯度経度から平面直角座標への変換の高精度化(これまでは10m程度の誤差があったが10cm以下に). その他の不具合の修正
2002年1月31日 日射環境の計算機能を追加.ベクトルファイルのマージの高速化
2002年1月23日 ベクトル図形のタイプ(point, line, areaなど)の相互変換や領域の内外反転などの機能を追加
2002年1月15日 図形間の「飛び石距離」を求める機能を追加
2002年1月11日 ベクトルファイルの属性変数間の演算機能を追加
2002年1月10日 ベクトルファイルとラスタファイルの座標軸の平行移動と回転を行う機能を追加
2002年1月9日 ベクトルファイルの統合(マージ)機能と,生物の分布域拡大過程の簡単なシミュレーションを行う機能を追加
2001年12月29日 複数のラスタファイルの統合や変数間の演算を行う機能を追加
2001年12月27日 北海道地図(株)の10mメッシュ標高データ(GISMAP Terrain)を読み込む機能を追加
2001年12月26日 気象庁の1kmメッシュ気候値のデータを読み込む機能を追加
2001年12月25日 [経緯度電卓]と国土地理院「数値地図50mメッシュ(標高)」のデータを読み込む機能を追加
2001年12月19日 国土地理院「細密数値情報(10mメッシュ土地利用)」のデータを読み込む機能を追加
2001年12月5日 斜に撮影した写真を入力する機能を追加
2001年9月19日 データのチェックの強化
2001年9月18日 polygon処理の不具合を修正.これ以前の版を利用している場合は再ダウンロードをお願いします.
2001年5月25日 公開